Adversarial Search
Adversarial search
is search when there is an "enemy" or "opponent" changing the state of the problem every step
in a direction you do not want.
Examples: Chess, business, trading, war.
You change state, but then you don't control the next state.
Opponent will change the next state in a way:
- unpredictable
- hostile to you
You only get to change (say) every alternate state.
The
Minimax
algorithm
tries to predict the opponent's behaviour.
It predicts the opponent will take the
worst action
from our viewpoint.
We are MAX - trying to maximise our score / move to best state.
Opponent is MIN - tries to minimise our score / move to worst state for us.
Example of Minimax with exhaustive search
The
Game of Nim:
At each move the player must divide a
pile of tokens into 2 piles of
different sizes.
The first player who is unable to make a move loses the game.
With a small number of tokens,
this game
is small enough for us to show an exhaustive search using Minimax.

The
entire
state space for a 7-token game.
Image courtesy of
Ralph Morelli.
See
Luger Fig 4.19
There are precisely 3 end states,
2 where person who starts wins, 1 where person who went 2nd wins:

Green - Person who starts wins.
Blue - Person who went 2nd wins.
Can exhaustively search the space.
Problem is figuring out what opponent will do.
If opponent MIN goes first, then:
Green - MIN wins - state has value 0 for us.
Blue - MAX wins - state has value 1.

Propagate these values back up.
Image courtesy of
Ralph Morelli.
Note 3-3-1 is missing its value, as we can see on
Luger Fig 4.20
Note 5-1-1 has value 0 not 1,
because it is MIN's turn, and they will take us to 4-1-1-1
not to 3-2-1-1.
Whereas 6-1 has value 1 not 0 because it is our turn.
If it is MIN's turn, parent value is the worst of its children.
If it is MAX's turn, parent value is the best of its children.
-
Note 2nd player always wins!
-
Person who goes first can never win unless 2nd player makes error.
-
This is different if no. of tokens different to 7.
See discussion.
4.4.2 Minimax (to fixed depth)
If we cannot do exhaustive search,
consider
doing minimax to a predefined depth
("minimax to fixed
ply
depth",
"n-ply look-ahead")
Leaves
of graph below will probably not terminate in a win/loss.
So have to give them
heuristic estimate of their value.
Note: The heuristic is applied to leaves only, not to higher levels.
Higher levels get their values by propagating leaf values upwards.
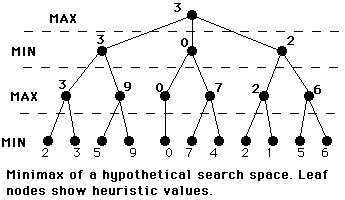
Image courtesy of Ralph Morelli.
See Luger Fig 4.21
At MAX level, we will always pick best.
At MIN level, opponent will always pick worst for you.
Here, we (MAX) start.
From start state, best we can do in 3 plies is get to state with estimated value 3.
Horizon effect
Horizon effect:
A state may look promising according to the heuristic
(e.g. I capture one of opponent's pieces)
but actually lead to disaster later on, beyond the horizon.
e.g. Heuristic says leaf is 9.
If you expand children of leaf, you find heuristic = 0 for all of them.
(Or, more likely, heuristic = 0 for one of them, but it is opponent's go, so parent must be 0.)
In general, we cannot avoid such effects because of:
- Imperfect heuristics
(a perfect heuristic would be an
oracle
telling you exactly how to win the game).
- Opponent moves us to a bad state beyond the "horizon".
One strategy:
Do some special extra deep searching for states that look exceptionally good.
Alpha-beta pruning
is a way of pruning the space.
Rather than search the entire space to fixed depth,
we can get rid of branches if we know they won't be picked.

Image courtesy of Ralph Morelli.
See
Luger Fig 4.26
-
See state B:
It's our turn, so B will have value at least 5.
But this is more than 3, so we know at state A, opponent will never pick B.
B sub-tree can be pruned.
Q. So we prune one child of B? So what? (Are all prunings of just one child?)
- At D, opponent's turn.
They will choose 0 or something worse.
But that means at C we will never choose D over A.
D tree can be pruned.
- Likewise, E will be 2 or worse.
So at C we will never choose E over A.
E tree can be pruned.
Pruning is good:
Calculating the heuristic evaluation of a state takes
time (consider chess).
It is good if we can avoid evaluating many states.
Lucky and unlucky orderings
It
depends on the ordering how much can be pruned.
If we search B
after searching its sibling (of value 3), we can prune it,
but not if it happened to come
before.
A lucky ordering and you could prune a lot.
An unlucky ordering and you have to visit all states.
Q. Reverse all orderings.
What prunings will then be done?
{kind=link}
{kind=link}
{kind=link}
{kind=link}