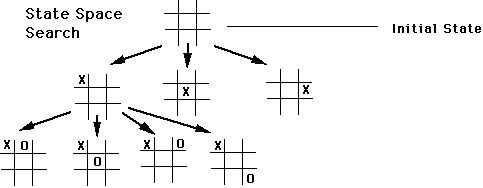
State space representation of a problem:
See Luger Fig 4.1
Symmetry reduction may require a lot of work by the human.
But worth it if it reduces search problem (sometimes massively).
We write code to do the transform, search and transform back.
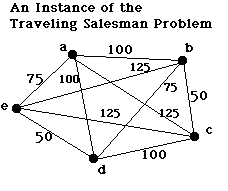
Travelling salesman problem.
Start at A, visit all cities, return to A.
Links show cost of each trip (distance, money).
Find trip with minimum cost.
Solution is a path.
e.g. [A,D,C,B,E,A]
Image courtesy of
Ralph Morelli.
See
Luger Fig 3.9
Q. What is the shortest path?
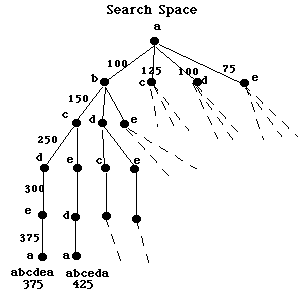
Q. What assumption did we make?
Q. When do we stop the search?
Luger changes his numbers to show example of "Nearest neighbour" heuristic failing on Travelling salesman problem:
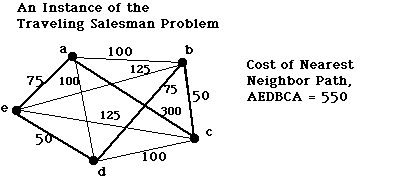
Image courtesy of
Ralph Morelli.
See
Luger Fig 3.11
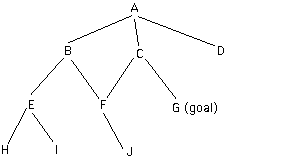
Depth-first search:
Start at A. Search state space systematically until find goal.
When multiple children, go down 1st child.
If fails, back to parent, down 2nd child, and so on.
Image courtesy of
Ralph Morelli.
See
Luger Fig 3.14
Note there are multiple paths to F.
If F has already been found to be a dead-end when we went there from B,
the algorithm should not go there a second time (from C).
However not a great example here since C can see goal so won't go to F anyway.
Definitions:
function newchildren ( state )
{
returns not all the children of state,
but the new ones to look at
i.e. those not on DE, SL or NSL
}
SL := [Start] // CS is part of the chain
NSL := [Start]
DE := []
CS := Start
while NSL not empty do
{
if CS = goal
return SL
else if newchildren(CS) not empty
{
place newchildren(CS) on NSL
CS := first element of NSL // move down to new state
add CS to SL // CS is part of the chain
}
else // newchildren(CS) empty, so backtrack
{
while (SL not empty) and (CS == first element of SL)
{
add CS to DE
remove first element of SL
remove first element of NSL
CS := first element of NSL
}
add CS to SL
}
}
AFTER CS SL NSL DE
ITERATION
0 A [A] [A] []
1 B [B A] [B C D A] []
2 E [E B A] [E F B C D A] []
3 H [H E B A] [H I E F B C D A] []
Now the first backtrack:
4 I [I E B A] [I E F B C D A] [H]
Now I is dead and so is parent E
5 F [F B A] [F B C D A] [E I H]
6 J [J F B A] [J F B C D A] [E I H]
7 C [C A] [C D A] [B F J E I H]
Here we only add G to NSL, since F is already in DE:
8 G [G C A] [G C D A] [B F J E I H]
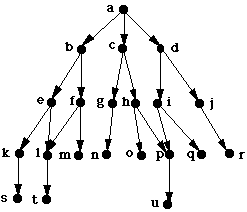
Depth-first search examines the nodes in the order:
A, B, E, K, S, L, T, F, M, C, G, N, H, O, P, U, D, I, Q, J, R
Need to:
Breadth-first search does each level first before moving lower, examines the nodes in the order:
A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, UNeed to:
Definitions:
Algorithm:
function newchildren ( state )
{
return children of state that are not already on OPEN or CLOSED
}
OPEN := [Start]
CLOSED := []
while OPEN not empty
{
remove LHS state from OPEN, call it X
if X is goal
return success
else
{
put X on CLOSED
put newchildren(X) on RHS of OPEN
}
}
Trace:
AFTER OPEN CLOSED
ITERATION
0 [A] []
1 [B C D] [A]
2 [C D E F] [B A]
3 [D E F G H] [C B A]
4 [E F G H I J] [D C B A]
5 [F G H I J K L] [E D C B A]
6 [G H I J K L M] [F E D C B A]
7 [H I J K L M N] [G F E D C B A]
...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}