input x = ( I1, I2, .., In)
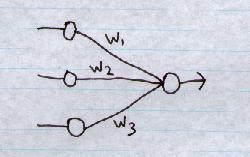
Input nodes (or units) are connected (typically fully) to a node (or multiple nodes) in the next layer.
A node in the next layer takes a weighted sum of all its inputs:
Summed input =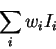
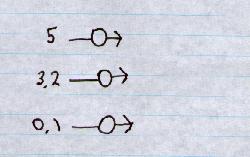
input x = ( I1, I2, I3) = ( 5, 3.2, 0.1 )
Summed input =
= 5 w1 + 3.2 w2 + 0.1 w3
The output node has a "threshold" t.
Rule: If summed input ≥
t, then it "fires"
(output y = 1).
Else (summed input
< t)
it doesn't fire (output y = 0).
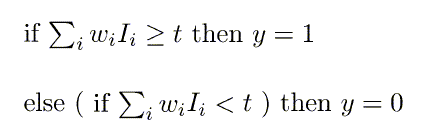
Obviously this implements a simple function from multi-dimensional real input to binary output. What kind of functions can be represented in this way?
We can imagine multi-layer networks. Output node is one of the inputs into next layer.
Perceptron has just 2 layers of nodes (input nodes and output nodes). Often called a single-layer network on account of having 1 layer of links, between input and output.
Note to make an input node irrelevant to the output, set its weight to zero. e.g. If w1=0 here, then Summed input is the same no matter what is in the 1st dimension of the input.
Weights may also become negative (higher positive input tends to lead to not fire).
Some inputs may be positive, some negative (cancel each other out).
A similar kind of thing happens in neurons in the brain (if excitation greater than inhibition, send a spike of electrical activity on down the output axon), though researchers generally aren't concerned if there are differences between their models and natural ones.
2 inputs, 1 output.
w1=1, w2=1, t=2.
Q. This is just one example. What is the general set of inequalities for w1, w2 and t that must be satisfied for an AND perceptron?
2 inputs, 1 output.
w1=1, w2=1, t=1.
Q. This is just one example. What is the general set of inequalities that must be satisfied for an OR perceptron?
What is the general set of inequalities that must be satisfied?
The perceptron is simply separating the input into 2 categories, those that cause a fire, and those that don't. It does this by looking at (in the 2-dimensional case):
w1I1 + w2I2 < tIf the LHS is < t, it doesn't fire, otherwise it fires. That is, it is drawing the line:
w1I1 + w2I2 = tand looking at where the input point lies. Points on one side of the line fall into 1 category, points on the other side fall into the other category. And because the weights and thresholds can be anything, this is just any line across the 2 dimensional input space.
So what the perceptron is doing is simply drawing a line across the 2-d input space. Inputs to one side of the line are classified into one category, inputs on the other side are classified into another. e.g. the OR perceptron, w1=1, w2=1, t=0.5, draws the line:
I1 + I2 = 0.5across the input space, thus separating the points (0,1),(1,0),(1,1) from the point (0,0):
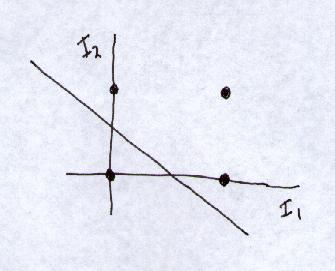
As you might imagine, not every set of points can be divided by a line like this. Those that can be, are called linearly separable.
In 2 input dimensions, we draw a 1 dimensional line. In n dimensions, we are drawing the (n-1) dimensional hyperplane:
w1I1 + .. + wnIn = t
XOR is defined as follows:
input output 0,0 0 0,1 1 1,0 1 1,1 0
Need:
1.w1 + 0.w2 cause a fire, i.e. >= t
0.w1 + 1.w2 >= t
0.w1 + 0.w2 doesn't fire, i.e. < t
1.w1 + 1.w2 also doesn't fire, < t
w1 >= t
w2 >= t
0 < t
w1+w2 < t
Contradiction.
Note: We need all 4 inequalities for the contradiction. If weights negative, e.g. weights = -4 and t = -5, then weights can be greater than t yet adding them is less than t, but t > 0 stops this.
A "single-layer" perceptron can't implement XOR. The reason is because the classes in XOR are not linearly separable. You cannot draw a straight line to separate the points (0,0),(1,1) from the points (0,1),(1,0).
Led to invention of multi-layer networks.
If the classification is linearly separable, we can have any number of classes with a perceptron.
For example, consider classifying furniture according to height and width:
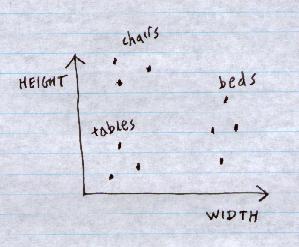
Each category can be separated from the other 2 by a straight line, so we can have a network that draws 3 straight lines, and each output node fires if you are on the right side of its straight line:
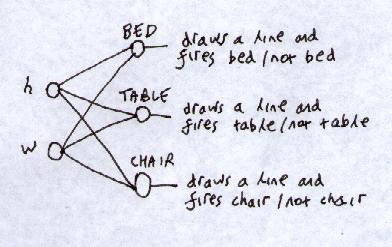
3-dimensional output vector.
Problem: More than 1 output node could fire at same time.
(Draw your lines. Then find a new point on the "right" side of 2 lines.)
We don't have to design these networks. We could have learnt those weights and thresholds, by showing it the correct answers we want it to generate.
Let
input x = ( I1, I2, .., In)
where each Ii = 0 or 1.
And let output y = 0 or 1.
Algorithm is:
Motivation for weight change rule:
Q. Why not just send threshold to minus infinity?
Q. Or send weights to plus infinity?
Note: Only need to increase wi's along the input lines that are active, i.e. where Ii=1. If Ii=0 for this exemplar, then the weight wi had no effect on the error this time, so it is pointless to change it (it may be functioning perfectly well for other inputs).
Hence algorithm is:
where C is some (positive) learning rate.
Note the threshold is learnt as well as the weights.
If O=y there is no change in weights or thresholds.
If Ii=0 there is no change in wi
| input x | network fires or not (y) | told correct answer (O) | what to do with w's | what to do with t |
| (0,1,0,0) | 0 | 1 | increase | reduce |
| (1,0,0,0) | 0 | 0 | no change | no change |
| (0,1,1,1) | 1 | 0 | reduce | increase |
| (1,0,1,0) | 1 | 0 | reduce | increase |
| (1,1,1,1) | 0 | 1 | increase | reduce |
| (0,1,0,0) | 1 | 1 | no change | no change |
| .... | .... | .... | .... | .... |
Note same input may be (should be) presented multiple times.
Convergence Proof - Rosenblatt, Principles of Neurodynamics, 1962.
i.e. Proved that:
If the exemplars used to train the perceptron are drawn from two linearly separable classes, then the perceptron algorithm converges and positions the decision surface in the form of a hyperplane between the two classes.
e.g. In 2 dimensions: We start with drawing a random line. Some point is on the wrong side. So we shift the line. Some other point is now on the wrong side. So we shift the line again. And so on. Until the line separates the points correctly.