Let
![]()
![]()
Proof: D's updates go:
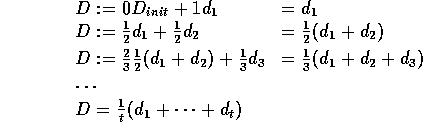
i.e. D is simply the average of all ![]() samples so far.
samples so far.
As ![]() ,
,
![]() .
.
![]()
![]()
to mean we adjust the estimate D once in the direction of the sample d.
![]()
where ![]() is the learning rate.
is the learning rate.
If
d < D
then the running average D goes down.
If
d > D
then the running average D goes up.
The notation:
![]()
means that over many such updates the estimate D converges to the expected value of the samples d.
Let D be updated by:
![]()
where d is bounded by ![]() ,
, ![]() ,
and the initial value of
,
and the initial value of
![]() .
Then:
.
Then:
![]()
Proof:
The highest D can be is if it is always updated with ![]() :
:
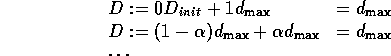
so ![]() .
Similarly
.
Similarly
![]() .
.
![]()
α must start at 1 to get rid of Dinit
Thereafter α can be anything from 0 to 1.
e.g. Imagine if
α
starts at 1, and
thereafter we let
α = 11.
Say we get a non-zero sample d once, then 0 forever.
Samples:
d, 0, 0, ....
Then D ends up with no apparent relationship to the samples d and 0.
And D is not even bounded.
It goes:
D := 0 + 1.d (since α starts at 1)
D := -10 d + 0
D := -10 (-10 d) + 0
D := - 103 d
D := 104 d
D := - 105 d
....
D not bounded
α not between 0 and 1 makes no sense.
An alternative approach is to build up not the average
of all samples, but a time-weighted sum of them,
giving more weight to the most recent ones.
This is accomplished by setting ![]() to be constant,
in which case D's updates go:
to be constant,
in which case D's updates go:
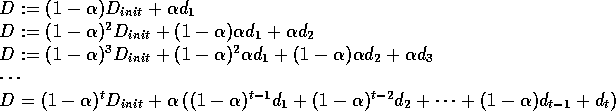
Since ![]() as
as ![]() ,
this weights more recent samples higher.
,
this weights more recent samples higher.
Typical learning rate might be
![]() .
.