On the larger-statespace Q-learning problems, random exploration takes too long to focus on the best actions, and also in a generalisation it will cause a huge amount of noise.
Problem - May only ever visit boring, mainstream states -
only small part of the entire
statespace.
Interesting area of statespace:
Hard to visit.
Need skilled sequence of actions to even get into these states.
But high r's.
When can't try all a in all x repeatedly in the finite time available:
Non-random exploration policy to do "smart" exploration in the finite time available. Get focused on a small no. of actions quickly. Get increasingly narrow-minded. Need a heuristic rule: some rule to focus on promising actions and states.
Note however that if we have any policy other than try all a's endlessly in all x's, we may be unlucky and miss the optimal actions. A heuristic is "a rule that may not work" (could be unlucky). In a large state-space we may have no choice and have to take that chance.
Given a state x, the agent tries out action a with probability:
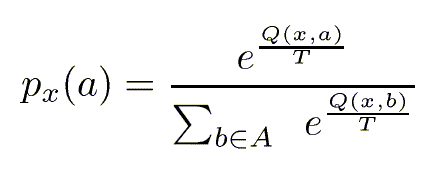
This is the Boltzmann or "soft max" distribution.
Highest Q will always be strictly more probable.
The temperature T controls the amount of exploration (the probability of executing actions other than the one with the highest Q-value). If T is high, or if Q-values are all the same, this will pick a random action. If T is low and Q-values are different, it will tend to pick the action with the highest Q-value.
The idea is to start with high exploration and decrease it to nothing as time goes on, so that after a while we are only exploring (x,a)'s that have worked out at least moderately well before.
At the start, Q is assumed to be totally inaccurate, so T is high (high exploration),
and actions all have a roughly equal chance of being executed.
T decreases as time goes on, and it becomes more and more likely to pick among the actions with the higher Q-values,
until finally, as we assume Q is converging to ![]() ,
T approaches zero (pure exploitation) and we tend to only pick the action with the highest Q-value:
,
T approaches zero (pure exploitation) and we tend to only pick the action with the highest Q-value:
![]()
That is, the agent acts according to a stochastic policy which as time goes on becomes closer and closer to a deterministic policy.
The exception is if there are joint winners, in which case the final policy will still be stochastic.
Say Q-values start at zero:
a a1 a2 a3 a4 a5 a6 Q(x,a) 0 0 0 0 0 0After some time, they are as follows (actions on 0 haven't been tried yet):
a a1 a2 a3 a4 a5 a6 Q(x,a) 0 3.1 -3.3 0 -3.5 3.3Now a high temperature would still pick actions randomly:
a a1 a2 a3 a4 a5 a6 p(a) 1/6 1/6 1/6 1/6 1/6 1/6
A moderate temperature would pick actions with probability something like:
a a1 a2 a3 a4 a5 a6 p(a) 0.2 0.3 0 0.2 0 0.3A low temperature would pick actions with probability:
a a1 a2 a3 a4 a5 a6 p(a) 0 0.1 0 0 0 0.9
Q. What other heuristics could we use, other than a heuristic based on the Q-values?
Could change it to distinguish between tried and untried actions:
e.g. After learning, policy is:
"Take best Q-value of an action that has been tried.".
Could change it to distinguish between tried and untried actions:
Be narrow-minded about a's we have tried,
random about a's we haven't tried?
Toss a coin and either pick random untried action
or else pick from tried actions with Boltzmann.
Note we do know that the action hasn't been tried,
because we are keeping a
different
α
for each pair (x,a).
then 0 is a neutral reward, but that doesn't mean it's a neutral Q-value.if (good thing) r = 1 else if (bad thing) r = -1 else r = 0
a a1 a2 a3 a4 a5 Q(x,a) -5 0 -1 -1 -5 n(x,a) 10 0 10 1 1What have we learnt? Which action should we take?
Stochastic control policy - Still have non-zero probabilities at run-time. - "Animals" - Usually, but not totally predictable - Don't "crash" or get stuck in infinite loop - Will eventually do something different
Admittedly, animals not getting stuck in infinite loop is also to do with: world changes (no absorbing states), internal state changes (hunger), ongoing competition among multiple drives, etc.
An absorbing state x is one for which, ![]() :
:
![]()
Once in x, the agent can't leave. The problem with this is that it will stop us visiting all (x,a) an infinite number of times. Learning stops for all other states once the absorbing state is entered, unless there is some sort of artificial reset of the experiment.
In a real environment, where x contains information from the senses, it is hard to see how there could be such thing as an absorbing state anyway, since the external world will be constantly changing irrespective of what the agent does. It is hard to see how there could be a situation in which it could be relied on to supply the same sensory data forever.
An artificial world could have absorbing states though.