Dublin City University, School of Computer Applications, Technical Report CA-0302. See full reference.
ABSTRACT
In the standard Agents paradigm, the agent "mind" (or decision-making mechanism) interacts with some environment or "world". Using this terminology of "mind" and "world", the Internet has been used to date as a means of: (a) being able to share worlds, and: (b) being able to construct multi-agent systems.
In the "World-Wide-Mind" (WWM) scheme introduced in [3], the Internet is used as a means of: (c) being able to share minds and parts of minds for use as components in large multi-mind systems. This is not multi-agent systems, but rather a "society of mind" within a single agent. Each sub-mind is not free to take actions - only the agent as a whole can take an action. One of the main reasons for this scheme is to assist in the construction of large, complex minds by teams of multiple, dispersed authors. Similar to how the Web enables publishing, the WWM scheme is designed to make it as easy as possible for an agent mind author to "publish" - to put their mind online for re-use in other societies of mind.
This paper describes the first implementation of a multi-level mind using this system. A brief description of the architecture and protocol currently used is presented. This expands considerably on the previous implementation [10].
Categories and Subject Descriptors
I.2.11 [Artificial Intelligence]: Distributed Artificial Intelligence - Intelligent agents
Keywords
Agent architectures, society of mind, Internet, agent communication protocols, agent programming environments, action selection, goal selection.
In the standard Agents model, the agent "mind" (or decision-making mechanism) interacts with (and makes decisions in) some environment or "world" (real or virtual). Using this terminology of "mind" and "world", the Internet has been used to date as a means of being able to share a common world to some degree.
Under the "World-Wide-Mind" scheme [3, 4], the Internet is used as a means of being able to share minds and parts of minds, for use as components in larger minds. To be precise, it is proposed that agent "minds" (and "worlds") be constructed as servers on the Internet. Re-use is done not by installing the software, but rather by using a remote service. The World-Wide-Mind system defines a protocol and architecture for communication with minds and worlds. The World-Wide-Mind is a term used for the system itself, and the set of worlds and minds currently online. In the lowest-common-denominator scheme we propose, minds and worlds are available online as servers, with a CGI interface, running over HTTP. They communicate using a simple set of XML requests and responses [6].
A World server may be queried for the current state of the world, and sent an action to be executed in that world. A Mind server may be sent a world state, and asked to suggest an action to be executed in this state. A large number of other queries may be defined (see [3] for many detailed examples), but the principle is that once an agent mind or world has been constructed as a server in this way, then it is possible to construct large multiple-mind systems, components of which are written in different languages by different authors on different platforms. Such systems cannot be readily constructed at present, and we suggest that only remote server re-use can make this possible, not local installation.
It is important to note that we are not talking about multi-agent systems, where each agent is free to take actions in the world as a separate entity. Rather we are talking about "society of mind" systems, where only the system as a whole can take an action. In other words, for many competing sub-minds suggesting actions, only one action can actually be taken and we have an action selection problem.
As an example, consider what we describe as an "Action Selection" or "MindAS server". This, when asked by a client to suggest an action, talks to several other Mind servers, and uses an algorithm defined by its author to specify which of the competing minds to "obey", given a certain set of criteria. It then returns that mind's suggested action as its own suggestion. The sub-minds exist in a "society of mind" [5], where they cannot actually take actions, but only suggest actions to a higher level in the hope that they will be executed. To the outside world, the MindAS server appears and functions as just another Mind server. It may itself be used remotely as just one sub-mind among many by another, even higher-level MindAS server. We can then run the top-level MindAS server as a single agent mind in an agent world, which is also online as a server.
In general, we address some fundamental issues with current AI practice:
One of the unique features of this scheme is to make it as easy as possible for agent authors to "publish" their minds and worlds online for re-use remotely. In this way, the WWM is best compared to the Web infrastructure, which made it easy to publish documents online. Ideally, for example, an AI researcher would be able to publish their algorithms for re-use online without having to learn any network programming at all. This is in contrast to most Agent models, which assume an interest in Networks. As a result, much interesting work in AI is not online, and may never be, unless a change in approach is taken.
It is this feature (of needing to appeal to as many authors as possible) that makes the WWM work so different to almost all Agents work. All technology involving a particular programming language (e.g. Java) or requiring the learning of particular programming skills (e.g. sockets) has to be rejected. Our focus is therefore on CGI, where the Mind or World author need only know how to repeatedly read plain text from stdin and write plain text to stdout. A stock CGI program, that can be downloaded from the World-Wide-Mind portal site [11], will perform the interaction with the client, so the author does not even need to know how to write CGI scripts.
Object-based distributed systems such as CORBA do allow for multiple platforms and languages, but again seem to assume an ability in network programming, which would rule them out here. Our approach is closer to the generic XML/HTTP protocol SOAP [9], and indeed we are considering recasting the WWM as an application of SOAP (provided this does not lead to increased complexity).
Minds and worlds are available online as "servers". What this means in a technical sense is that each mind or world will have a URL, which points at the CGI script used to communicate with the mind or world, something like:
http://www.site.edu/cgi-bin/staff/myuser/wwm/mymind
In order to communicate with the mind or world, HTTP requests are made to these CGI scripts. The request is in a subset of XML that we call "AI Markup Language" (AIML), defined in [6]. The CGI scripts parse the XML request, process it, generate an XML response, and exit. HTTP and CGI were chosen for their ready availability (anyone who wants can get free web hosting, even for CGI scripts) and ease of use (no new programming language to learn). XML was chosen for its simple, plain text and above all else extendable nature. Future changes to the definition of the XML queries should not break old servers. A sample query would be as follows. The Mind server is queried for what action to perform, given that the world is in some state:
<request type="GetAction" runid="RUNID">
<data name="x">
world state
</data>
</request>
It generates the XML response:
<response type="GetAction" runid="RUNID">
<data name="a">
suggested action
</data>
</response>
For more queries see [3, 6]. The format of state and action is not defined in AIML but is defined by the world server. Different definitions will co-exist. XML will allow many elegant ways of converting between different definitions. For discussion of state conversions see [7], and action conversions see [8].
In the simplest case, a client makes the requests, and passes the information between the mind and world. The mind and world servers do not contact each other directly. In other words, a client application is needed to "run" a Mind server in some World server. This is essentially the "browser" for the WWM. Such a client is easy to write, or one could download it from the World-Wide-Mind portal site [11], where work is in progress on a number of clients. The normal invocation of the client would be (from the command-line):
$ client (world url) (mind url)
to start that Mind running in that World. The world would be repeatedly queried for state, the state sent to the mind to suggest an action, the action sent to the world for execution, and so on indefinitely. A graphical display would show what was happening, with a "Stop" button to end the run.
A server may call another server, and an example would be the case of the MindAS server above, which will query several mind servers based on its query criteria. For further examples of servers calling other servers see [3]. In such cases, the calling server appears as just another client, and the normal client-server model is preserved.
In line with our need to make it as easy as possible to write servers, we would imagine that the server author, to call another server, again needs no network programming ability, but can call the client "browser" with certain arguments:
$ client -onestep (url)
to send a single XML query to that URL and get the response, and then exit. The client here would read an XML query from stdin, send it to that URL, write the XML response to stdout, and exit.
There is a distinction between the CGI script (which must terminate after each XML query) and the actual mind or world program (we call this the WWM server), which may remain persistent in between XML queries.
In our first implementation, the WWM server is persistent, waiting for the next query to come in. When a CGI script is called, it writes the XML query to a file, alerts the persistent WWM server somehow, and then waits for an output file to be created. When the WWM server has written the XML response to the output file, it alerts the CGI script, which then outputs this file back to the client and exits. The WWM server continues on in memory, waiting for the next query. To avoid file conflicts, a simple system of lockfiles is used. There are obviously many other possible approaches to this, such as:
The lockfiles approach is perhaps the one demanding the least amount of knowledge from the server author. In our implementation, the programs create or delete a lockfile, based on what stage in the handshake the request was at (Table 1).
|
Time |
WWM Server |
CGI script |
|---|---|---|
|
1 |
Write out world state to output file |
Wait for lock file to exist... |
|
2 |
Create lock file |
|
|
3 |
Wait for lock file to not exist. |
Read world state from output file |
|
4 |
|
Write Action to Input File |
|
5 |
|
Delete Lock File |
|
6 |
Read Action from Input File |
|
|
7 |
Execute Action in the World. |
|
As an initial implementation, 2 minds and 2 worlds were adapted to this system. Both worlds were simple "grid worlds" with a mobile agent, a "nest", several pieces of "food" and a mobile "predator". The agent is then given a "mind" in which to take decisions (make moves) in the world. The details of these "worlds" are not important here. What is important is that they were written by 2 different authors in different programming languages (C++ and Java), and are hosted on separate remote HTTP servers, with no agreement other than the format of the XML queries. First we show one mind interacting with one world (Figure 3). The client repeats the following for as many steps as required:
As well as the URL that XML requests should be sent to, the World server has a "display URL", which is an ordinary web page displaying what is happening in the world as actions are sent to it for execution. This is, of course, optional. Even if the server has no display URL, the client has the ability to output the world state as the world reports it.
Mind A (Java) was able to explore World B (C++), and Mind B (C++) was able to explore World A (Java). It makes no difference what language the mind or world is written in, provided each server generates the correct XML. We have not yet built a multiple-mind system where parts of the same mind are written in different languages by different authors, but we foresee no particular problems with this. It will still be encouraging when this is first done, though, particularly when we get the first authors from outside of our start group.
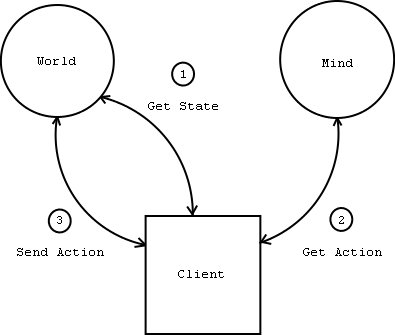
Figure 3: A Mind runs in a World.
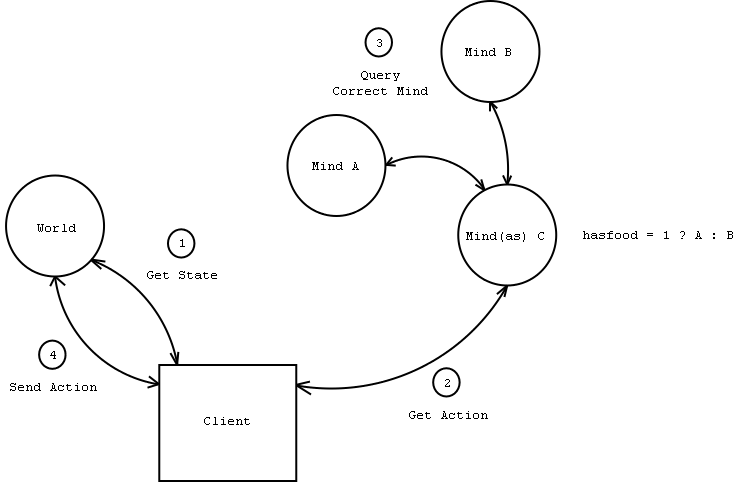
Figure 4: A MindAS server runs in a World.
The sample MindAS server shown in Figure 4 is simply an abstraction of Mind A and Mind B. It uses its criterion to determine which Mind to "obey". It then returns the action suggested by that Mind to the client as its action. To A and B, the requests from the MindAS server are exactly the same as requests direct from a client. In our case, the MindAS server will obey Mind A if the "has food" parameter is true. Otherwise it will obey Mind B. The criteria for deciding which mind to obey can be basically anything. A server may implement any general-purpose algorithm to talk to other servers, provided that it itself responds to the XML queries expected of it.
The whole point of remote re-use is to enable massive re-use. Local installation of other people's AI projects involves compatibility problems with operating systems, versions, platforms, files, libraries, environments and programming languages - and as a result, generally does not happen. We view it as highly unlikely that local installation will lead to widespread re-use in this domain.
But by definition remote re-use has inherent speed limitations. It remains to be seen exactly which problems can be approached in a realistic time using this approach and which cannot. e.g. Problems where there is a small to moderate amount of communication, and a large amount of remote processing, should be the (large) niche in which this will work.
One of the main current areas of work of the WWM project is the conversion of several well-known minds and worlds to this system, to provide an example, and perhaps an incentive for other researchers and laboratories to use this system. This will be a cumulative effort, becoming more and more useful as more servers go online.
Our other focus is on defining the WWM protocol itself - the XML queries and the CGI interface - in the simplest possible way so as to enable authors to put their work online. Our target audience is not so much the Agents community as the entire field of AI whose work cannot as of now be used remotely. We aim to change this situation, so that AI becomes a vast collective enterprise in which no one individual understands all of the components of the large distributed minds that are being built.