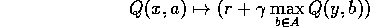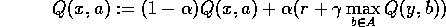School of Computing. Dublin City University.
Online coding site:
![]() Ancient Brain
Ancient Brain
coders JavaScript worlds
School of Computing. Dublin City University.
Online coding site:
![]() Ancient Brain
Ancient Brain
coders JavaScript worlds
A Reinforcement Learning (RL) agent senses a world, takes actions in it, and receives numeric rewards and punishments from some reward function based on the consequences of the actions it takes. By trial-and-error, the agent learns to take the actions which maximize its rewards. For a broad survey of the field see [Kaelbling et al., 1996].
Watkins [Watkins, 1989] introduced the method of reinforcement learning called Q-learning.
The agent exists within a world that can be modelled as a
Markov
Decision Process (MDP).
It observes discrete states of the world x ( ![]() , a finite set)
and can execute discrete actions a (
, a finite set)
and can execute discrete actions a ( ![]() , a finite set).
Each discrete time step, the agent observes state x, takes action a,
observes new state y, and receives immediate reward r.
Transitions are probabilistic,
that is, y and r are drawn from stationary probability distributions
, a finite set).
Each discrete time step, the agent observes state x, takes action a,
observes new state y, and receives immediate reward r.
Transitions are probabilistic,
that is, y and r are drawn from stationary probability distributions ![]() and
and ![]() , where
, where
![]() is the probability that taking action a in state x will lead to state y
and
is the probability that taking action a in state x will lead to state y
and ![]() is the probability that taking action a in state x will generate reward r.
We have
is the probability that taking action a in state x will generate reward r.
We have ![]() and
and ![]() .
.
Note that having a reward every time step is actually no restriction. The classic delayed reinforcement problem is just a special case with, say, most rewards zero, and only a small number of infrequent rewards non-zero.
The transition probability can be viewed as a conditional probability.
Where ![]() are the values of x,a at time t,
the Markov property is expressed as:
are the values of x,a at time t,
the Markov property is expressed as:
![]()
and the stationary property is expressed as:
![]()
The simple deterministic world is a special case with all transition probabilities equal to 1 or 0.
For any pair x,a,
there will be a unique state ![]() and a unique reward
and a unique reward ![]() such that:
such that:
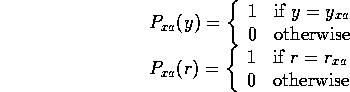
The set of actions available may differ from state to state. Depending on what we mean by this, this may also possibly be represented within the model, as the special case of an action that when executed (in this particular state, not in general) does nothing:
![]()
for all actions a in the "unavailable" set for x .
![]() This would not exactly be "do nothing" since you would still get the reward
for staying in x.
This would not exactly be "do nothing" since you would still get the reward
for staying in x.
Later in this thesis, we will be considering how agents react when the actions of other agents are taken, actions that this agent does not recognise. Here the action is recognised by the agent, just in some states it becomes unavailable.
In the multi-agent case, an agent could assume that an unrecognised action has the effect of "do nothing" but it might be unwise to assume without observing.
When we take action a in state x, the reward we expect to receive is:
![]()
Typically, the reward function is not phrased in terms of what action we took but rather what new state we arrived at, that is, r is a function of the transition x to y. The general idea is that we can't reward the right a because we don't know what it is - that's why we're learning. If we knew the correct a we could use ordinary supervised learning.
Writing r = r(x,y), the probability of a particular reward r is:
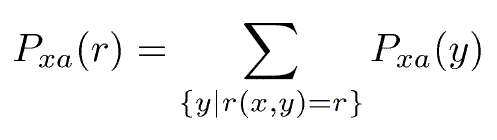
and the expected reward becomes:
![]()
That is, normally we never think in terms of ![]() - we only think in terms of
- we only think in terms of ![]() .
Kaelbling [Kaelbling, 1993] defines a globally consistent world
as one in which, for a given x,a, E(r) is constant.
This is equivalent to requiring that
.
Kaelbling [Kaelbling, 1993] defines a globally consistent world
as one in which, for a given x,a, E(r) is constant.
This is equivalent to requiring that ![]() is stationary
(hence, with the typical type of reward function,
is stationary
(hence, with the typical type of reward function, ![]() stationary).
stationary).
In some models, rewards are associated with states, rather than with transitions, that is, r = r(y). The agent is not just rewarded for arriving at state y - it is also rewarded continually for remaining in state y. This is obviously just a special case of r = r(x,y) with:
![]()
and hence:
![]()
Rewards r are bounded by ![]() ,
where
,
where ![]() (
( ![]() would be a system where the reward was the same
no matter what action was taken. The agent would always behave randomly
and would be of no use or interest).
Hence for a given x,a,
would be a system where the reward was the same
no matter what action was taken. The agent would always behave randomly
and would be of no use or interest).
Hence for a given x,a, ![]() .
.
The agent acts according to a policy ![]() which tells it what action
to take in each state x.
A policy that specifies a unique action to be performed
which tells it what action
to take in each state x.
A policy that specifies a unique action to be performed ![]() is called a deterministic policy
- as opposed to a stochastic policy, where an action a is chosen from a distribution
is called a deterministic policy
- as opposed to a stochastic policy, where an action a is chosen from a distribution ![]() with probability
with probability ![]() .
.
A policy that has no concept of time is called a stationary or memory-less policy - as opposed to a non-stationary policy (e.g. "do actions a and b alternately"). A non-stationary policy requires the agent to possess memory. Note that stochastic does not imply non-stationary.
Following a stationary deterministic policy ![]() ,
at time t, the agent observes state
,
at time t, the agent observes state ![]() , takes action
, takes action ![]() ,
observes new state
,
observes new state ![]() , and receives reward
, and receives reward ![]() with expected value:
with expected value:
![]()
The agent is interested not just in immediate rewards,
but in the total discounted reward.
In this measure, rewards received n steps into the future
are worth less than rewards received now, by a factor of ![]() where
where ![]() :
:
![]()
The discounting factor
γ
defines how much expected future rewards
affect decisions now.
Genuine immediate reinforcement learning is the special case ![]() ,
where we only try to maximize immediate reward.
Low γ
means pay little attention to the future.
High γ
means that potential future rewards have a major influence on decisions now
- we may be willing to trade short-term loss for long-term gain.
Note that for
,
where we only try to maximize immediate reward.
Low γ
means pay little attention to the future.
High γ
means that potential future rewards have a major influence on decisions now
- we may be willing to trade short-term loss for long-term gain.
Note that for ![]() , the value of future rewards always eventually becomes negligible.
The expected total discounted reward
if we follow policy
, the value of future rewards always eventually becomes negligible.
The expected total discounted reward
if we follow policy ![]() forever,
starting from
forever,
starting from ![]() , is:
, is:
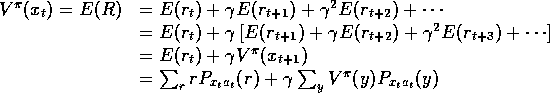
![]() is called the value of state x under policy
is called the value of state x under policy ![]() .
The problem for the agent is to find an optimal policy - one that maximizes the total discounted expected reward
(there may be more than one policy that does this).
Dynamic Programming (DP) theory [Ross, 1983]
assures us of the existence of an optimal policy for an MDP,
also (perhaps surprisingly) that there is a stationary and deterministic optimal policy.
In an MDP one does not need memory to behave optimally,
the reason being essentially that the current state contains all information about what is going to happen next.
A stationary deterministic optimal policy
.
The problem for the agent is to find an optimal policy - one that maximizes the total discounted expected reward
(there may be more than one policy that does this).
Dynamic Programming (DP) theory [Ross, 1983]
assures us of the existence of an optimal policy for an MDP,
also (perhaps surprisingly) that there is a stationary and deterministic optimal policy.
In an MDP one does not need memory to behave optimally,
the reason being essentially that the current state contains all information about what is going to happen next.
A stationary deterministic optimal policy ![]() satisfies, for all x:
satisfies, for all x:
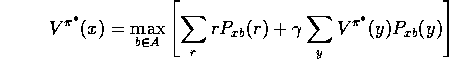
For any state x, there is a unique value ![]() , which is the best that an agent can do from x.
Optimal policies
, which is the best that an agent can do from x.
Optimal policies ![]() may be non-unique, but the value
may be non-unique, but the value ![]() is unique.
All optimal policies
is unique.
All optimal policies ![]() will have:
will have:
![]()
The strategy that the Q-learning agent adopts is to build up Quality-values (Q-values) Q(x,a) for each pair (x,a).
If the transition probabilities ![]() ,
, ![]() are explicitly known,
Dynamic Programming finds an optimal policy by starting with random V(x) and random Q(x,a)
and repeating forever (or at least until the policy is considered good enough):
are explicitly known,
Dynamic Programming finds an optimal policy by starting with random V(x) and random Q(x,a)
and repeating forever (or at least until the policy is considered good enough):
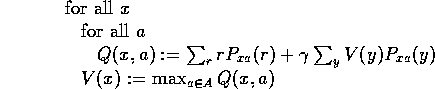
This systematic iterative DP process is obviously an off-line process. The agent must cease interacting with the world while it runs through this loop until a satisfactory policy is found.
The problem for the Q-learning agent is to find an optimal policy
when ![]() ,
, ![]() are initially unknown
(i.e. we are assuming when modelling the world that some such transition probabilities exist).
The agent must interact with the world to learn these probabilities.
Hence we cannot try out states and actions systematically as in Dynamic Programming.
We may not know how to return to x
to try out a different action (x,b)
- we just have to wait until x happens to present itself again.
We will experience states and actions rather haphazardly.
are initially unknown
(i.e. we are assuming when modelling the world that some such transition probabilities exist).
The agent must interact with the world to learn these probabilities.
Hence we cannot try out states and actions systematically as in Dynamic Programming.
We may not know how to return to x
to try out a different action (x,b)
- we just have to wait until x happens to present itself again.
We will experience states and actions rather haphazardly.
Fortunately, we can still learn from this. In the DP process above, the updates of V(x) can in fact occur in any order, provided that each x will be visited infinitely often over an infinite run. So we can interleave updates with acting in the world, having a modest amount of computation per timestep. In Q-learning we cannot update directly from the transition probabilities - we can only update from individual experiences.
|
Core Q-learning algorithm:In 1-step Q-learning, after each experience, we observe state y, receive reward r, and update:
(remember notation). For example, in the discrete case, where we store each Q(x,a) explicitly in lookup tables, we update:
|
Since the rewards are bounded, it follows that the Q-values are bounded (Theorem B.2). Note that we are updating from the current estimate of Q(y,b) - this too is constantly changing.
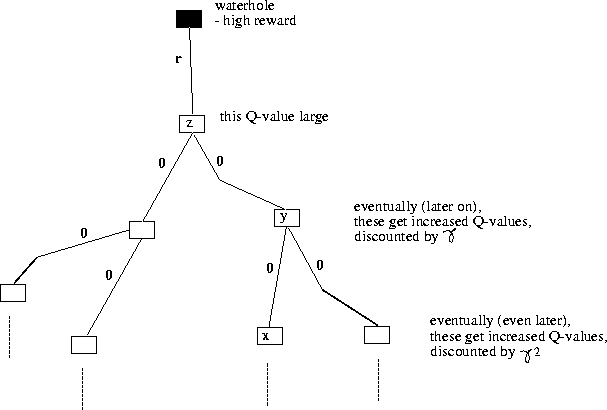
Figure 2.1: How Q-learning works (adapted from a talk by Watkins).
Imagine that ![]() ,
but from state z the agent can take an action c that yields a high reward
,
but from state z the agent can take an action c that yields a high reward ![]() (Watkins used the example of an animal arriving at a waterhole).
Then Q(z,c) will be scored high,
and so V(z) increases.
Q(y,b) does not immediately increase, but next time it is updated, the increased V(z) is factored in, discounted by
(Watkins used the example of an animal arriving at a waterhole).
Then Q(z,c) will be scored high,
and so V(z) increases.
Q(y,b) does not immediately increase, but next time it is updated, the increased V(z) is factored in, discounted by ![]() .
Q(y,b)
and hence V(y) increase - y is now valuable because from there you can get to z.
Q(x,a) does not immediately increase, but next time it is updated, the increased V(y) is factored in, discounted by
.
Q(y,b)
and hence V(y) increase - y is now valuable because from there you can get to z.
Q(x,a) does not immediately increase, but next time it is updated, the increased V(y) is factored in, discounted by ![]() (hence V(z) is effectively factored in, discounted by
(hence V(z) is effectively factored in, discounted by ![]() ).
Q(x,a) increases because it led to y, and from there you can get to z, and from there you can get a high reward.
In this way the rewards are slowly propagated back through time.
).
Q(x,a) increases because it led to y, and from there you can get to z, and from there you can get a high reward.
In this way the rewards are slowly propagated back through time.
In this way, the agent can learn chains of actions. It looks like it can see into the future - though in reality it lives only in the present (it cannot even predict what the next state will be). Using the language of ethology [Tyrrell, 1993], this is how credit is propagated from a consummatory action back through the chain of appetitive actions that preceded it.
Q-learning solves the temporal credit assignment problem without having to keep a memory of the last few chains of states. The price you pay is that it demands repeated visits. Weir [Weir, 1984] argues that the notion of state needs to be expanded into a trajectory or chain of states through the statespace, but this example shows that such a complex model is not needed for the purposes of time-based behavior.
As Q-learning progresses, the agent experiences the world's transitions.
It does not normally build up an explicit map of ![]() of the form
of the form ![]() .
Instead it sums the rewards to build up the probably more useful mapping
.
Instead it sums the rewards to build up the probably more useful mapping ![]() .
In fact this exact mapping itself is not stored, but is only one component of the Q-values,
which express more than just immediate reward.
If
.
In fact this exact mapping itself is not stored, but is only one component of the Q-values,
which express more than just immediate reward.
If ![]() the Q-values express the exact map
the Q-values express the exact map ![]() .
.
The agent also experiences the state transitions
and can if it chooses build up a world model, that is, estimates of ![]() .
This would be the map
.
This would be the map ![]() ,
whose implementation would demand a much larger statespace.
Rewards can be coalesced of course but states can't.
There is no such thing as E(y)
(except for the special case of a deterministic world
,
whose implementation would demand a much larger statespace.
Rewards can be coalesced of course but states can't.
There is no such thing as E(y)
(except for the special case of a deterministic world ![]() ).
).
Moore [Moore, 1990] applies machine learning to robot control using a state-space approach,
also beginning without knowledge of the world's transitions.
His robot does not receive reinforcement, but rather learns ![]() in situations where the designer can specify what the desired next y should be.
in situations where the designer can specify what the desired next y should be.
Moore works with a statespace too big for lookup tables. He stores (x,a,y) triples (memories) in a nearest-neighbour generalisation. With probabilistic transitions, the agent may experience (x,a,y) at some times and (x,a,z) at others. There may then be a conflict between finding the needed action: x,y predicts a, and predicting what it will do: x,a predicts not y. In fact Moore shows that this conflict can arise even in a deterministic world after limited experience (where the exemplars you use for prediction are not exact but are the nearest neighbours only).
Sutton's DYNA architecture [Sutton, 1990, Sutton, 1990a] uses reinforcement learning
and builds a model
in a deterministic world
with a statespace small enough to use lookup tables.
It just fills in the map ![]() .
.
The point that Q-learning illustrates though is that learning an explicit world model is not necessary for the central purpose of learning what actions to take. Q-learning is model-free ([Watkins, 1989, §7] calls this primitive learning). We ignore the question of what x,a actually lead to, and the problem of storage of that large and complex mapping, and just concentrate on scoring how good x,a is.
The agent can perform adaptively in a world without understanding it. All it tries to do is sort out good actions to perform from bad ones. A good introduction to this approach is [Clocksin and Moore, 1989], which uses a state-space approach to control a robot arm. Instead of trying to explicitly solve the real-time inverse dynamics equations for the arm, Clocksin and Moore view this as some generally unknown nonlinear I/O mapping and concentrate on filling in the statespace by trial and error until it is effective. They argue against constructing a mathematical model of the world in advance and hoping that the world will broadly conform to it (with perhaps some parameter adjustment during interaction). But here we could learn the entire world model by interaction. What would be the advantage of doing this?
For a single problem in a given world, a model is of limited use. As [Kaelbling, 1993] points out, in the time it takes to learn a model, the agent can learn a good policy anyway. The real advantage of a model is to avoid having to re-learn everything when either the world or problem change:
Sutton shows in [Sutton, 1990a] how a model can be exploited to deal with a changing world. His agent keeps running over the world model in its head, updating values based on its estimates for the transition probabilities, as in Dynamic Programming. As it senses that the world has changed it will start to do a backup in its head. For example, in the waterhole scenario above, when it senses (by interaction with the world) that state z no longer leads to the waterhole, it will start to do a backup in its head, without having to wait to revisit y and x in real life.
A standard usage of reinforcement learning is to have some known desired state y, at which rewards are given, leaving open what states the agent might pass through on the way to y. The agent learns by rewards propagating back from y (as in §2.1.6). The problem with this is we then can't give the agent a new explicit goal z and say "Go there". We have to re-train it to go to z.
In Sutton's model, when the agent suddenly (in real life) starts getting rewards at state z it will immediately update its model and the rewards will rapidly propagate back in its mental updates, quicker than they would if the states had to be revisited in real life. Kaelbling's Hierarchical Distance to Goal (HDG) algorithm [Kaelbling, 1993a] addresses the issue of giving the agent new explicit z goals at run-time.
In the discrete case, we store each Q(x,a) explicitly, and update:
![]()
for some learning rate ![]() which controls how much weight we give to the reward just experienced,
as opposed to the old Q-estimate.
We typically start with
which controls how much weight we give to the reward just experienced,
as opposed to the old Q-estimate.
We typically start with ![]() , i.e. give full weight to the new experience.
As
, i.e. give full weight to the new experience.
As ![]() decreases, the Q-value is building up an average of all experiences,
and the odd new unusual experience won't disturb the established Q-value much.
As time goes to infinity,
decreases, the Q-value is building up an average of all experiences,
and the odd new unusual experience won't disturb the established Q-value much.
As time goes to infinity, ![]() , which would mean
no learning at all, with the Q-value fixed.
, which would mean
no learning at all, with the Q-value fixed.
Remember that because in the short term we have inaccurate Q(y,b) estimates,
and because (more importantly) in the long term we have probabilistic transitions anyway,
the return from the same (x,a) will vary.
See §A.1 to understand how a decreasing ![]() is generally used to take a converging expected value of a distribution.
is generally used to take a converging expected value of a distribution.
We use a different ![]() for each pair (x,a),
depending on how often we have visited state x and tried action a there.
When we are in a new area of state-space (i.e. we have poor knowledge),
the learning rate is high.
We will have taken very few samples, so the average of them will be highly influenced
by the current sample.
When we are in a well-visited area of state-space, the learning rate is low.
We have taken lots of samples, so the single current sample can't make much difference to the
average of all of them (the Q-value).
for each pair (x,a),
depending on how often we have visited state x and tried action a there.
When we are in a new area of state-space (i.e. we have poor knowledge),
the learning rate is high.
We will have taken very few samples, so the average of them will be highly influenced
by the current sample.
When we are in a well-visited area of state-space, the learning rate is low.
We have taken lots of samples, so the single current sample can't make much difference to the
average of all of them (the Q-value).
[Watkins and Dayan, 1992] proved that the discrete case of Q-learning
will converge to an optimal policy under the following conditions.
The learning rate ![]() , where
, where ![]() ,
should take decreasing (with each update) successive values
,
should take decreasing (with each update) successive values ![]() , such that
, such that
![]() and
and
![]() .
The typical scheme (and the one used in this work) is,
where
.
The typical scheme (and the one used in this work) is,
where ![]() is the number of times Q(x,a) has been visited:
is the number of times Q(x,a) has been visited:
![]()
If each pair (x,a) is visited an infinite number of times, then
[Watkins and Dayan, 1992] shows that for lookup tables
Q-learning converges to a unique set of values ![]() which define a stationary deterministic optimal policy.
Q-learning is asynchronous and sampled - each Q(x,a) is updated one at a time,
and the control policy may visit them in any order, so long as it visits them
an infinite number of times.
Watkins [Watkins, 1989] describes his algorithm
as "incremental dynamic programming by a
Monte Carlo method".
which define a stationary deterministic optimal policy.
Q-learning is asynchronous and sampled - each Q(x,a) is updated one at a time,
and the control policy may visit them in any order, so long as it visits them
an infinite number of times.
Watkins [Watkins, 1989] describes his algorithm
as "incremental dynamic programming by a
Monte Carlo method".
After convergence,
the agent then will maximize its total discounted expected reward
if it always takes the action with the highest ![]() -value.
That is, the optimal policy
-value.
That is, the optimal policy ![]() is defined by
is defined by ![]() where:
where:
![]()
Then:
![]()
![]() may be non-unique, but the value
may be non-unique, but the value ![]() is unique.
is unique.
Initial Q-values can be random.
![]() typically starts at 0, wiping out the initial Q-value in the first update
(Theorem A.1).
Although the
typically starts at 0, wiping out the initial Q-value in the first update
(Theorem A.1).
Although the ![]() term may factor in an inaccurate initial Q-value from elsewhere,
these Q-values will themselves be wiped out by their own first update,
and poor initial samples have no effect
if in the long run samples are accurate (Theorem A.2).
See [Watkins and Dayan, 1992] for the proof that initial values are irrelevant.
term may factor in an inaccurate initial Q-value from elsewhere,
these Q-values will themselves be wiped out by their own first update,
and poor initial samples have no effect
if in the long run samples are accurate (Theorem A.2).
See [Watkins and Dayan, 1992] for the proof that initial values are irrelevant.
Note that ![]() will satisfy the conditions for any
will satisfy the conditions for any
![]() .
The typical
.
The typical ![]() goes from 1 down to 0,
but in fact if the conditions hold, then for any t,
goes from 1 down to 0,
but in fact if the conditions hold, then for any t,
![]() and
and
![]() ,
so
,
so ![]() may start anywhere along the sequence.
That is,
may start anywhere along the sequence.
That is, ![]() may take successive values
may take successive values ![]() (see Theorem A.2).
(see Theorem A.2).
Q-learning is an attractive method of learning because of the simplicity of the computational demands per timestep, and also because of this proof of convergence to a global optimum, avoiding all local optima. One catch though is that the world has to be a Markov Decision Process. As we shall see, even interesting artificial worlds are liable to break the MDP model.
Another catch is that convergence is only guaranteed when using lookup tables, while the statespace may be so large as to make discrete lookup tables, with one cell for every combination of state and action, require impractically large amounts of memory. In large statespaces one will want to use some form of generalisation, but then the convergence proof no longer holds.
Finally, even if the world can be approximated by an MDP, and our generalisation can reasonably approximate lookup tables, the policy that Q-learning finds may be surprising. The optimal solution means maximising the rewards, which may or may not actually solve the problem the designer of the rewards had in mind. The agent may find a policy that maximizes the rewards in unexpected and unwelcome ways (see [Humphrys, 1996, §4.1] for an example). Still, the promise of RL is that designing reward functions will be easier than designing behavior. We will return to the theme of designing reward functions in §4.3.1 and §4.4.3.
Also note that Q-learning's infinite number of (x,a) visits can only be approximated. This is not necessarily a worry because the important thing is not the behavior and Q-values at infinity, but rather that in finite time it quickly gets down to focusing on one or two actions in each state. We usually find that a greedy policy (execute the action with the highest Q-value) is an optimal policy long before the Q-values have converged to their final values.
In real life, since we cannot visit each (x,a) an infinite number of times, and then exploit our knowledge, we can only approximate Q-learning. We could do a large finite amount of random exploration, then exploit our knowledge. In fact this is the simple method I use on the smaller Q-learning statespaces in this work.
On the larger-statespace Q-learning problems, random exploration takes too long to focus on the best actions, and also in a generalisation it will cause a huge amount of noise, so instead I use a method that interleaves exploration and exploitation. The idea is to start with high exploration and decrease it to nothing as time goes on, so that after a while we are only exploring (x,a)'s that have worked out at least moderately well before.
The specific control policy used is a standard one in the field and originally comes from [Watkins, 1989] and [Sutton, 1990]. The agent tries out actions probabilistically based on their Q-values using a Boltzmann or soft max distribution. Given a state x, it tries out action a with probability:
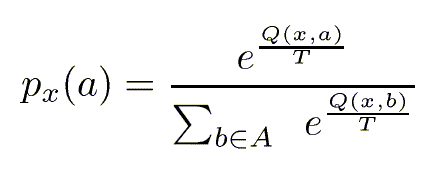
Note that ![]() whether the Q-value is positive or negative,
and that
whether the Q-value is positive or negative,
and that ![]() .
The temperature T controls the amount of exploration
(the probability of executing actions other than the one with the highest Q-value).
If T is high, or if Q-values are all the same, this will pick a random action.
If T is low and Q-values are different, it will tend to pick the action with
the highest Q-value.
.
The temperature T controls the amount of exploration
(the probability of executing actions other than the one with the highest Q-value).
If T is high, or if Q-values are all the same, this will pick a random action.
If T is low and Q-values are different, it will tend to pick the action with
the highest Q-value.
At the start, Q is assumed to be totally inaccurate, so T is high (high exploration),
and actions all have a roughly equal chance of being executed.
T decreases as time goes on, and it becomes more and more likely to pick among the actions with the higher Q-values,
until finally, as we assume Q is converging to ![]() ,
T approaches zero (pure exploitation) and we tend to only pick the action with the highest Q-value:
,
T approaches zero (pure exploitation) and we tend to only pick the action with the highest Q-value:
![]()
That is, the agent acts according to a stochastic policy which as time goes on becomes closer and closer to a deterministic policy.
![]() I should have mentioned here the possibility of joint winners,
in which case the final policy will still be stochastic.
I should have mentioned here the possibility of joint winners,
in which case the final policy will still be stochastic.
In fact, while I use simple random exploration (no Boltzmann) to learn the Q-values on the small statespaces, when it came to testing the result instead of using a deterministic strict highest Q I used a low temperature Boltzmann. Strict determinism can lead to a creature with brittle behavior. If there are a number of more-or-less equally good actions with very little difference in their Q-values, we should probably rotate around them a little rather than pick the same one every time.
An absorbing state x is one for which, ![]() :
:
![]()
Once in x, the agent can't leave. The problem with this is that it will stop us visiting all (x,a) an infinite number of times. Learning stops for all other states once the absorbing state is entered, unless there is some sort of artificial reset of the experiment.
In a real environment, where x contains information from the senses, it is hard to see how there could be such thing as an absorbing state anyway, since the external world will be constantly changing irrespective of what the agent does. It is hard to see how there could be a situation in which it could be relied on to supply the same sensory data forever.
No life-like artificial world would have absorbing states either (the one I use later certainly does not).
Return to Contents page.