XML and HTML
Machine readable v. human readable content.
- Binary v. Plain text
- Plain text formats like XML and HTML are much less efficient than binary format,
but plain text is much more flexible.
- XML -
Describe content in structured way.
- Content might be on web or offline files.
- Should XML be mixed with HTML?
- Basic idea of machine-readable web:
If prices of products on a website are marked like this:
<price> $29.99 </price>
then a program can easily find them.
-
Question is if there should be separate machine readable and human readable pages.
-
XML data can be very precisely defined (and programs can reject it if it does not match the definition).
- XML format is described in:
- DTD
(Document type definition)
- XSD
(XML Schema Definition)
XML example
Example XML file:
test.ajax.xml
Pure data file (not web page).
Contains
US states.
<?xml version="1.0"?>
<choices xml:lang="EN">
<item><label>Alabama</label><value>AL</value></item>
...
<item><label>Wyoming</label><value>WY</value></item>
</choices>
XML example - Microsoft Office XML
Part of a Word file in XML format (DOCX):

See explanation:
Microsoft Office XML file formats.
Note invention of own tags:
...
<entry>
<title>by Nathan Coley</title>
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/jeremydp/3992143711/"/>
<id>tag:flickr.com,2005:/photo/3992143711</id>
<published>2009-10-08T12:00:32Z</published>
<updated>2009-10-08T12:00:32Z</updated>
<dc:date.Taken>2009-10-03T21:59:32-08:00</dc:date.Taken>
<content type="html"> .... </content>
<author>
<name>jeremyDP</name>
<uri>http://www.flickr.com/people/jeremydp/</uri>
</author>
<link rel="enclosure" type="image/jpeg" href="http://farm3.static.flickr.com/2479/3992143711_1353c6f932_m.jpg" />
<category term="paris" scheme="http://www.flickr.com/photos/tags/" />
<category term="2009" scheme="http://www.flickr.com/photos/tags/" />
<category term="butteschaumont" scheme="http://www.flickr.com/photos/tags/" />
<category term="nuitblanche" scheme="http://www.flickr.com/photos/tags/" />
<category term="nathancoley" scheme="http://www.flickr.com/photos/tags/" />
</entry>
...
Machine readable web
RSS (XML web feeds)
There is support in many programming languages for parsing XML / HTML.
The problem is they
may fail on badly-formed XML / HTML (i.e. lots of HTML).
- Javascript
- jQuery
- Shell - Command-line tools that you can use in shell scripts
- Java -
Parsing HTML in Swing
- List of HTML parsers
- Many in this list are designed to be
error-tolerant and able to parse the badly-formed HTML
that is found "in the wild".
See ones called names like "soup" and "tidy".
- Some are program libraries
(e.g. Java libraries).
Some are stand-alone command-line tools.
- The "tag soup" concept.
- The
TagSoup
Java library
by John Cowan
Strategy for parsing HTML:
- Use error-tolerant readers to convert badly-formatted HTML to
well-formatted HTML.
- Can now parse the well-formatted HTML with other, more picky programs like xpath.
As the web matured, the HTML standards people started to consider the problem of bad HTML.
- The problem:
- Existing HTML clients (browsers) are forgiving.
You can be sloppy, skip end tags,
etc. and it will still display.
You can use any case or mixed case.
- Badly-formatted HTML is everywhere, and can be hard to parse.
- The proposed solution:
-
XHTML
tried to change this
- make HTML unforgiving and case-sensitive.
-
The idea was to make it:
- Easier for programs to process content.
(Extract sub-sections of content,
re-post content to other sites, mash up multiple items, etc.)
- Easier to process/display on small, low-memory devices (mobile browsers).
- Entirely predictable what will happen when a program processes your data.
No ambiguity in what the program will do.
- Why the Web needs fixing
- The arguments, in 2007, at xhtml.com.
- The fact that the xhtml.com
site is now gone (!) says it all.


Screenshot
from
XHTML ebook
shows the utopian vision of XHTML.
-
"XML requires user-agents to fail when encountering malformed XML".
Q. Would you use such a browser?
i.e. One that wouldn't allow you view a favourite site
because it had malformed XHTML.
Or would you (as the whole history of the Web shows)
simply move quietly to a different, more tolerant browser?
Anyone making an unforgiving browser won't have a lot of users.
- "The recommendation for browsers to post an error
rather than attempt to render malformed content
should help eliminate malformed content."
Yeah, right.
Because authors have nothing better to do.
Re-write the Web?
- I was always sceptical of the XHTML vision:
-
Yes, it is true that if we all migrated to XHTML,
it would make it easier for programs to process content.
But are you going to re-write 10 billion web pages?
- As for the idea of making it easier to display on small, mobile devices:
Well, not only does
my tablet
display malformed HTML beautifully with no problem,
but so did
my old PDA
and
even
my old WAP phone!
- Martian Headsets, Joel Spolsky, March 17, 2008,
on HTML standards
- Maybe "the way the web "should have" been built would be to have very, very strict standards and every web browser should be positively obnoxious about pointing them all out to you and web developers that couldn't figure out how to be "conservative in what they emit" should not be allowed to author pages that appear anywhere until they get their act together.
But, of course, if that had happened, maybe the web would never have taken off like it did, and maybe instead, we'd all be using a gigantic Lotus Notes network operated by AT&T. Shudder."
- About the idea that old web pages need to "change" to conform to standards:
"Those websites are out of your control. Some of them were developed by people who are now dead.
...
The idealists don't care: they want those pages changed.
Some of those pages can't be changed. They might be burned onto CD-ROMs. Some of them were created by people who are now dead. Most of them created by people who have no frigging idea what's going on and why their web page, which they paid a designer to create 4 years ago, is now not working properly."
- Again, if the browser doesn't display the old pages, what will most people do?
That's right.
Dump the browser.

My first decent mobile Internet device:
XDA Exec
=
HTC Universal
(2005).
This had no problem rendering malformed HTML.
Strict, well-formed data is good (so long as not compulsory)
There is
a good rule:
"Be conservative in what you send, be liberal in what you accept".
i.e. For a new project, why not output strict, well-formed data (XHTML, or validated HTML).
It will make it easier for your team to re-purpose your content in the future.
I am only pointing out that this cannot be the entire world ("be liberal in what you accept"). One must also consider:
- Old pages.
- New pages written by people who do not conform to standards.
(You might say "amateurs".
Or you might say "people with other jobs".)
There are millions of such pages and sites.
There are new such pages and sites created every day.
Consider even just the web pages of
all computer lecturers at DCU.
How many validate their HTML?
Unlikely the web will ever be well-formed.
And maybe it doesn't matter.
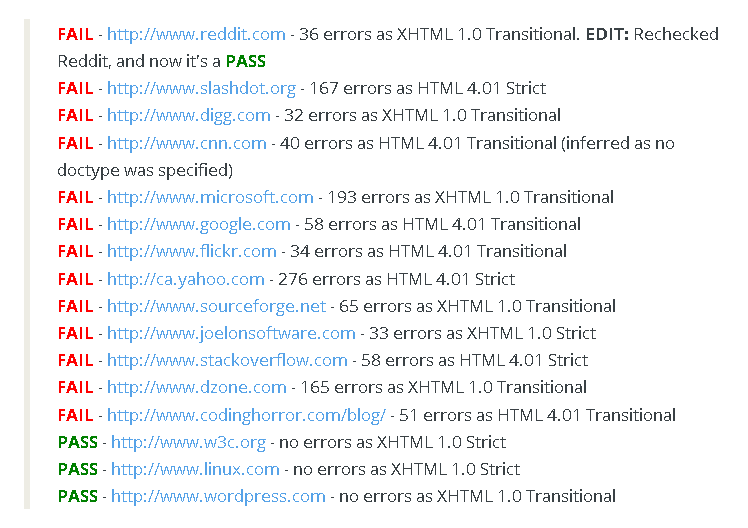 2009 post
2009 post
tries to validate HTML on major websites,
and suggests that
the majority of the web is malformed.
And it doesn't seem to matter.
-
Another post
explores the almost ludicrous nature of the forgiveness of errors in HTML, CSS and (often forgotten) Javascript.
-
Errors in Javascript code are everywhere, but are not even displayed. If you did display them, browsing would be painful:
"It's nearly impossible to navigate the web with JavaScript error notification enabled."
-
It's an interesting programming environment:
"I can't think of any other programming environment that goes to such lengths to avoid presenting error messages, that tries so hard to make broken code work, at least a little."
HTML5 instead of XHTML
- Instead of everyone moving from HTML to XHTML,
there was a strong demand to update HTML.
- HTML 5
- HTML versions
- HTML 4
was defined in 1997, updated 1999.
- Then there was a huge gap.
- HTML 5
was defined in 2014.
-
HTML 5 is fairly opposed to the XHTML idea.
- HTML 5 allows XHTML syntax, but does not enforce it.
-
It is tolerant like HTML 4.
It will not demand the XHTML features of
lower case tag names, quoting attributes, attribute has to have a value,
close all empty elements.
- Rather than reject badly-formed HTML,
HTML5 tries to define
the required processing for such documents.
- Many argue that
XHTML is dead.
-
List of HTML tags
shows (in red)
Obsolete and Deprecated tags under HTML 5.
Of course, browsers will go on supporting these forever.
- xhtml.com
pointed out that a spec can declare tags obsolete,
but that doesn't mean browsers should reject that tag.
"Specs don't need to be backwards compatible.
Instead, the better solution is that user-agents should be backwards compatible, by supporting multiple specs."
That is, browsers can support HTML5 and HTML4 and HTML3 and before.
- The Truth About HTML5,
by
R.J. Owen and Luke Stevens
(2013)
has a little history.
See
Page 2.
JSON instead of XML
- Even in the domain of machine-readable data, XML has lost its dominance.
- JSON
is a machine-readable text format that is super-easily-parsed by JavaScript.
Because it almost is JavaScript data already.
- Since a lot of the code doing the parsing of data on the Web
was actually JavaScript,
JSON has risen in popularity
instead of XML.
Human-readable web and machine-readable web stay separate
- In practice, instead of mixing Machine-readable web (XML, JSON)
and Human-readable web (HTML)
they are often entirely separate services.
- e.g. Company provides:
- 5,000 URLs of human-readable HTML pages displaying products and prices.
- An API with feeds of XML or JSON machine-readable data containing products and prices.
Maybe the API allows a single URL returning all price data for whole website in machine-readable form,
of size a few M of text.
Remote client can grab this dump with one request
instead of making 5,000 separate requests for tiny machine-readable fragments.