So what should we start weights and thresholds at?
Note from graph of sigmoid function that large positive or negative Summed x has a very small slope dy/dx.
dy/dx = y(1-y), and at either end, one of these terms is near zero.
Hence for large absolute xk,
 is near zero,
and
is near zero,
and
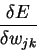 is near zero too.
is near zero too.
Large absolute Summed x (caused by large absolute weights) causes a small change in weights, slow learning.
Small weights give fast learning. All things being equal, small weights tend to put us in the middle of the sigmoid curve, the area of rapid change.
Small weights and fast learning is what we want at the start, when we know nothing.
Let all weights and thresholds start at zero.
Short version:
Multiple hidden nodes the same are useless. You can achieve the same effect with one hidden node and different weights. Consider the following.
Q.
A neural network has
1 input node, n hidden nodes, and 1 output node.
The weights on the input layer are all the same:
wij = W1.
The thresholds of the hidden nodes are all the same:
tj = T.
The weights on the output layer are all the same:
wjk = W2.
This network is equivalent to a network with
1 input node, 1 hidden node, and 1 output node,
where (wij, tj, wjk) =
what?
How small is "small"?
Like many other things to do with the neural network, we may need to experiment.
One way to stop this is for exemplar outputs to be 0.1 to 0.9, rather than 0 to 1.