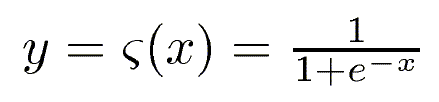Given Summed Input:
x =
The node produces output y according to the sigmoid function:
Note
e
and its
properties.
As x goes to minus infinity,
y goes to 0 (tends not to fire).
As x goes to infinity,
y goes to 1 (tends to fire):
At x=0, y=1/2
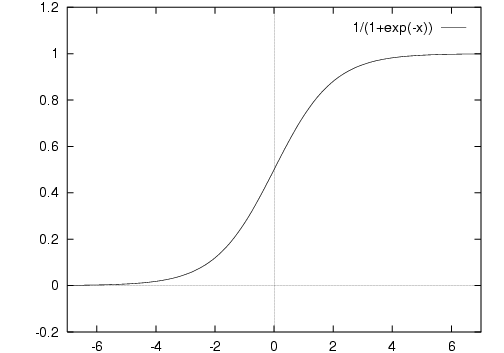
We can make this more and more threshold-like, or step-like, by increasing the weights on the links, and so increasing the summed input:
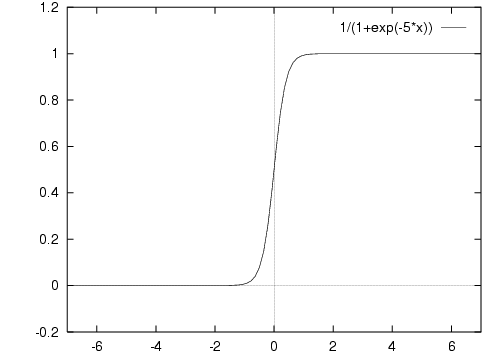
For any non-zero w, no matter how close to 0, ς(wx) will eventually be asymptotic to the lines y=0 and y=1.
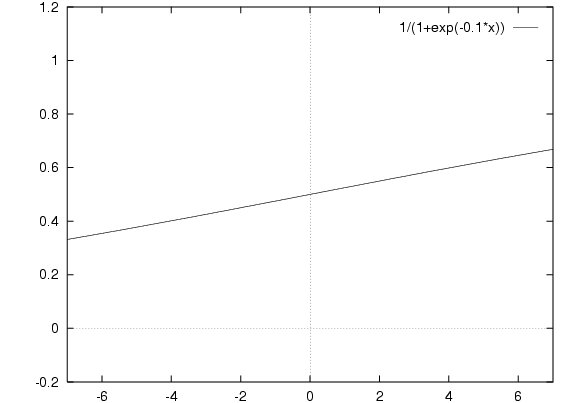
Is this linear? Let's change the scale:
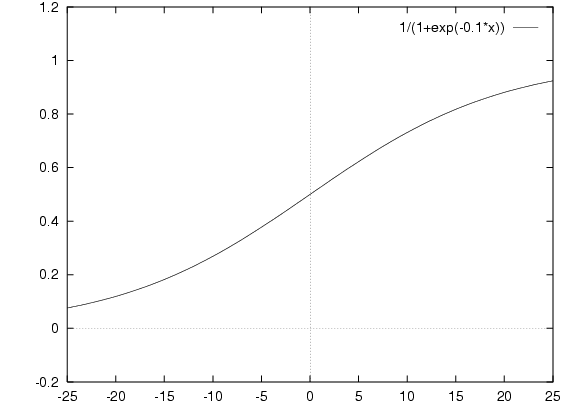
This is exactly same function.
So it's not actually linear, but note that
within the range -6 to 6
we can approximate a linear function with slope.
If x will always be within that range
then for all practical purposes we have
linear output with slope.
We can also, by changing the sign of the weights, make large positive actual input lead to large negative summed input and hence no fire, and large negative actual input lead to fire.
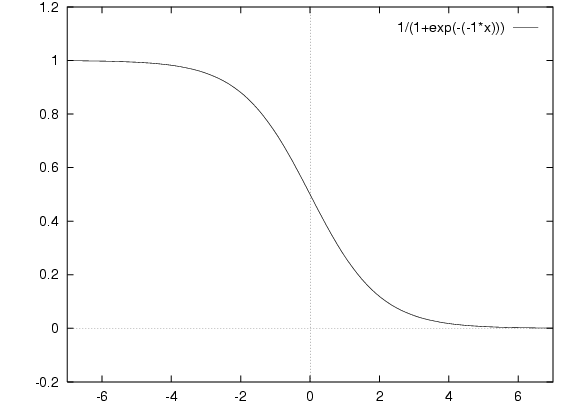
This is of course a threshold-like function still centred on zero. To centre it on any threshold we use:
y = ς(x-t)
where t is the threshold for this node. This threshold value is something that is learnt, along with the weights.
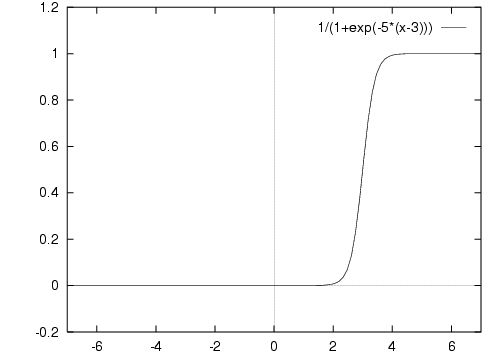
The "threshold" is now the centre point of the curve, rather than an all-or-nothing value.
y = ς(ax+b)
By varying b, we can have constant output y=c (slope zero) for any c between 0 and 1.
Cannot be linear with non-zero slope.
We are going to differentiate it to look at some properties.
Reminder - differentiation rules:
d/dx (fg) = f (dg/dx) + g (df/dx)
Quotient Rule:
d/dx (f/g) = ( g (df/dx) - f (dg/dx) ) / g2
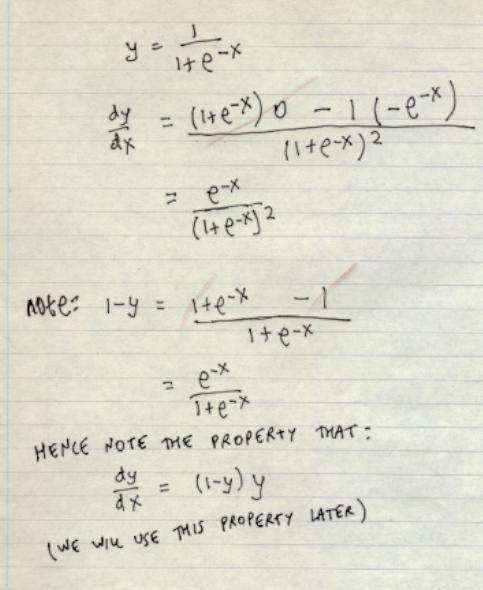
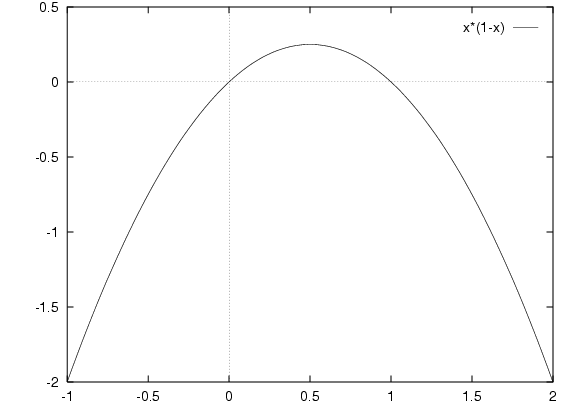
To prove this, take the next derivative and look for where it equals 0:
d/dy ( y (1-y) )
= y (-1) + (1-y) 1
= -y + 1 -y
= 1 - 2y
= 0 for y = 1/2
This is a maximum. There is no minimum.
y = ς(ax+b)a positive or negative, fraction or multiple
y = ς(z) where z = ax+b
dy/dx = dy/dz dz/dx
= y(1-y) a
if a positive, all slopes are positive,
steepest slope (highest positive slope) is at y = 1/2
if a negative, all slopes are negative,
steepest slope (lowest negative slope) is at y = 1/2
i.e. Slope is different value, but still steepest at y = 1/2