This would be the map ![]() ,
whose implementation would demand a large data structure.
,
whose implementation would demand a large data structure.
Recall that when learning Pxa(r),
instead of building
![]() we could build the simplified map
we could build the simplified map
![]() .
.
But we cannot do this with Pxa(y).
Rewards can be coalesced but states can't.
There is no such thing as E(y)
(except for the special case of a deterministic world
![]() ).
).
To build a model of the "laws of physics"
we need a huge data structure
x,a,y -> [0,1]
in which 99 % of the entries will be zero.
e.g. Let x = Waterhole is N, a = move N,
y = Waterhole is here.
Pxa(x) = 0.5
Pxa(y) = 0.5
Pxa(w) = 0
for all the millions of w other than x,y
Millions of them because the waterhole is actually only
1 dimension of the entire n-dimensional input state:
Pxa(w,*,*,*,...,*) = 0
e.g. Chess.
x = opening configuration of board
a = move white pawn
Opponent then moves.
Observe new state y
Pxa(y) = 0 for billions of states y
(e.g. all check states, all states without full no. of pieces)
In most worlds, for any given x,a pair, the probability of going to millions of y is zero.
Moore works with a statespace too big for lookup tables. He stores (x,a,y) triples (memories) in a nearest-neighbour generalisation. With probabilistic transitions, the agent may experience (x,a,y) at some times and (x,a,z) at others. There may then be a conflict between finding the needed action: x,y predicts a, and predicting what it will do: x,a predicts not y. In fact Moore shows that this conflict can arise even in a deterministic world after limited experience (where the exemplars you use for prediction are not exact but are the nearest neighbours only).
Sutton's DYNA architecture
[Sutton, 1990, Sutton, 1990a]
uses reinforcement learning
and builds a model
in a deterministic world
with a statespace small enough to use lookup tables.
It just fills in the map ![]() .
.
The point that Q-learning illustrates though is that learning an explicit world model is not necessary for the central purpose of learning what actions to take. Q-learning is model-free (Watkins calls this primitive learning). We ignore the question of what x,a actually lead to, and the problem of storage of that large and complex mapping, and just concentrate on scoring how good x,a is.
The agent can perform adaptively in a world without understanding it. All it tries to do is sort out good actions to perform from bad ones. A good introduction to this approach is [Clocksin and Moore, 1989], which uses a state-space approach to control a robot arm. Instead of trying to explicitly solve the real-time inverse dynamics equations for the arm, Clocksin and Moore view this as some generally unknown nonlinear I/O mapping and concentrate on filling in the statespace by trial and error until it is effective. They argue against constructing a mathematical model of the world in advance and hoping that the world will broadly conform to it (with perhaps some parameter adjustment during interaction).
But here we could learn the entire world model by interaction. What would be the advantage of doing this?
Sutton shows in [Sutton, 1990a] how a model can be exploited to deal with a changing world. His agent keeps running over the world model in its head, updating values based on its estimates for the transition probabilities, as in Dynamic Programming. As it senses that the world has changed it will start to do a backup in its head. For example, in the waterhole scenario, when it senses (by interaction with the world) that state z no longer leads to the waterhole, it will start to do a backup in its head, without having to wait to revisit y and x in real life.
A standard usage of reinforcement learning is to have some known desired state y, at which rewards are given, leaving open what states the agent might pass through on the way to y. The agent learns by rewards propagating back from y. The problem with this is we then can't give the agent a new explicit goal z and say "Go there". We have to re-train it to go to z.
In Sutton's model, when the agent suddenly (in real life) starts getting rewards at state z it will immediately update its model and the rewards will rapidly propagate back in its mental updates, quicker than they would if the states had to be revisited in real life. Kaelbling's Hierarchical Distance to Goal (HDG) algorithm addresses the issue of giving the agent new explicit z goals at run-time.
As Q-values improve in accuracy, we need to re-visit updates we already did. We previously updated:
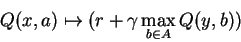
The r was accurate.
The y was accurate.
Q(y,b) was totally inaccurate, however,
so once we learn an accurate value for Q(y,b),
we should really do this update again.
If we do store all memories and/or build up a world model, then we can re-do updates in our head, factoring in more accurate Q(y,b)'s.
e.g. In waterhole above,
we have explicitly stored the fact that y,b -> z
So as soon as
maxd Q(z,d) increases
(i.e. as soon as we discover action c),
we can reflect this change in Q(y,b),
without having to revisit y.
And we know that x,a -> y
so we can further update Q(x,a)
without having to revisit x.
Need to be careful about computational cost of this backtracking:
Probabilistic world means replay has to be fair:
A model may be more trouble than it's worth.
Explicit memories / replay seems good if some experiences are costly / rare. Don't want to forget them.
Explicit memories: Store all (x,a,y,r) memories for replay. Like photo memory. Do we have memories we are not aware of?
Implicit memories: Q(x,a) and Pxa(y) data structures reflect our past experience implicitly. No photo memory of actual experiences.
Do we do replay offline? Are these perhaps best done when the brain is not otherwise occupied? i.e. Perhaps best done when asleep? "Dreaming"? Things you can do offline.
Model is useful for changing world - easier to spot that dynamics of the world have changed if you have a prediction of what they should have been.
Still tricky to detect because MDP allows probabilistic world.
Model useful when give the agent new goals in the same world: "Go to state z".
![]()
Note that immediately the command c changes, we jump to an entirely new state for the slave and it may start doing something entirely different.
Given a slave that has learnt this, the master will learn that it can reach a state by issuing the relevant command. Using the notation x,a -> y, it will note that the following will happen:
![]()
That is, the master learns that the world has state transitions ![]() such that
such that ![]() is high.
It then learns what actions to take based on whatever it wants to get done.
Note that it can learn a chain - that
is high.
It then learns what actions to take based on whatever it wants to get done.
Note that it can learn a chain - that ![]() is high
and then
is high
and then ![]() is very high.
So the model does not fail if the slave takes a number of steps to fulfil the order.
is very high.
So the model does not fail if the slave takes a number of steps to fulfil the order.
The master may be able to have a simpler state space as a result of this delegation.
For example, in the AntWorld,
![]() can order
can order ![]() to get it to the state where it is not carrying food
(so that it can then set off for a new reward).
to get it to the state where it is not carrying food
(so that it can then set off for a new reward).
![]() does not need to sense the nest (and so has a smaller input statespace).
does not need to sense the nest (and so has a smaller input statespace).