Figure illustrates how Q-learning deals with delayed reinforcement.
Action a leads from x to y.
Action b leads from y to z.
Action c leads from z to waterhole and reward.
Let all Q-values start at 0.
r > 0
γ > 0
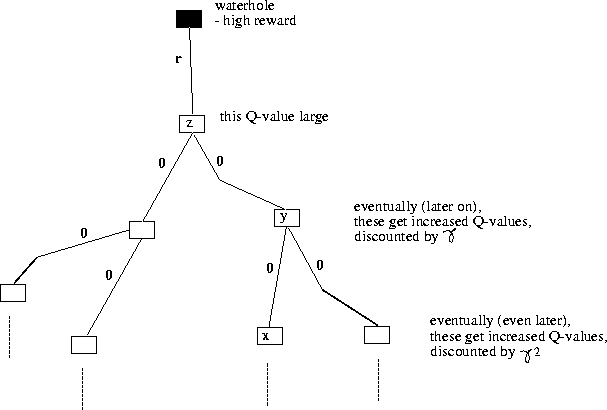
How Q-learning works (adapted from a talk by Watkins).
|
Imagine that ![]() ,
but from state z the agent can take an action c that yields a high reward
,
but from state z the agent can take an action c that yields a high reward ![]() (Watkins used the example of an animal arriving at a waterhole).
Then Q(z,c) will be scored high,
and so V(z) increases.
Q(y,b) does not immediately increase, but next time it is updated, the increased V(z) is factored in, discounted by
(Watkins used the example of an animal arriving at a waterhole).
Then Q(z,c) will be scored high,
and so V(z) increases.
Q(y,b) does not immediately increase, but next time it is updated, the increased V(z) is factored in, discounted by ![]() .
Q(y,b)
and hence V(y) increase - y is now valuable because from there you can get to z.
Q(x,a) does not immediately increase, but next time it is updated, the increased V(y) is factored in, discounted by
.
Q(y,b)
and hence V(y) increase - y is now valuable because from there you can get to z.
Q(x,a) does not immediately increase, but next time it is updated, the increased V(y) is factored in, discounted by ![]() (hence V(z) is effectively factored in, discounted by
(hence V(z) is effectively factored in, discounted by ![]() ).
Q(x,a) increases because it led to y, and from there you can get to z, and from there you can get a high reward.
In this way the rewards are slowly propagated back through time.
).
Q(x,a) increases because it led to y, and from there you can get to z, and from there you can get a high reward.
In this way the rewards are slowly propagated back through time.
Spelling it out:
Go from y to z 100 times, but never went from z to waterhole:
Q(y,b) = 0
Eventually, in state z we took action c:
Q(z,c) = r
[2]
At this point this is the only non-zero Q-value in the whole system.
Next time we take action b to go from y to z,
we factor in the (best) Q-value of the next state:
Q(y,b) = 0 + γ ( r )
[1]
= γ r
Next time we go from x to y, this value is propagated back:
Q(x,a) = 0 + γ ( γ r )
[1]
= γ2 r
If r is only non-zero reward in system,
then even 100 steps away from waterhole
it will take action heading towards waterhole,
since:
γ100 r > 0
[3]
Q-value = 0 + γ 0
+ γ2 0
+ ...
+ γ100 r
In this way, the agent can learn chains of actions. It looks like it can see into the future - though in reality it lives only in the present (it cannot even predict what the next state will be). Using the language of ethology, this is how credit is propagated from a consummatory action back through the chain of appetitive actions that preceded it.
Q-learning solves the temporal credit assignment problem without having to keep a memory of the last few chains of states. The price you pay is that it demands repeated visits.
Here's how it works precisely. We try b repeatedly in y and it leads to r=0 and new state z. As of now, z is of no interest. The updates for Q(y,b) go:
Q(y,b) := 0 (0) + 1 ( 0 + γ 0 ) = 0Q(y,b) = 0 and α(y,b) = 1/n.
Q(y,b) := 1/2 (0) + 1/2 ( 0 + γ 0 ) = 0
Q(y,b) := 2/3 (0) + 1/3 ( 0 + γ 0 ) = 0
...
Eventually, some time in state z, we try action c
and get a reward.
We get this reward the
very first time we try (z,c).
The updates for Q(z,c) go:
[2]
Q(z,c) := 0 (0) + 1 ( r + γ 0 )Next time we try (y,b), again we don't get reward, but now it does lead somewhere interesting - z now has a non-zero Q-value:
= r
...
Q(y,b) := (n-1)/n (0) + 1/n ( 0 + γ r )
= 1/n γ r
...
Q. How about Q(x,a) now? What is the update the next time we try (x,a)?
Let's carry on.
Next time you update Q(y,b):
Q(y,b) := n/(n+1) (1/n γ r) + 1/(n+1) ( 0 + γ r )and again:
= 2/(n+1) γ r
Q(y,b) := (n+1)/(n+2) (2/(n+1) γ r) + 1/(n+2) ( 0 + γ r )with increasing t:
= 3/(n+2) γ r
Q(y,b) = t / (t+n-1) γ r(n-1) constant - the number of times we scored Q(y,b) before we discovered z was good.
As t
-> infinity
Q(y,b)
->
γ r
Conclusion - It doesn't matter in the long run that we updated Q(y,b) any finite number of times before learning about z.
Q. Prove Q(x,a) -> γ2 r
If not absorbing state, what might Q(z,c) really look like. Consider these two possibilities:
One answer to all this:
Q(y,b) -> γ Q
Q(x,a) -> γ2 Q
etc., as before
γ100 r > 0it will be:
γ100 r > γ102 r(If you don't move towards the waterhole, you move away, but then you can move back in 1 more step). (*)
(*) Assuming you can move back, i.e. this is two-way, not one-way.
Normally (depending on the MDP problem of course)
the good action doesn't have a Q-value massively
bigger than the bad actions,
only a bit bigger.
Because Q-learning measures you making the wrong choice now
and then the right choice afterwards
(rather than measuring you
making the wrong choice, followed by the wrong choice, etc.).
Q-value of stupid action = rstupid + γ maxclever Q(y,b)
Q-learning pushes the limits of stimulus-response behaviour. By associating x with y (and y with z and so on) it shows how an apparently "stimulus-response" agent can behave as if it has a past and future.
The whole trend of modern behaviour-based AI is to push the limits of what stimulus-response can do before postulating more complex models (though we all agree that more complex models are needed eventually). See Discussion of Stimulus-Response.