The agent acts according to a policy ![]() which tells it what action
to take in each state x.
A policy that specifies a unique action to be performed
which tells it what action
to take in each state x.
A policy that specifies a unique action to be performed ![]() is called a deterministic policy
- as opposed to a stochastic policy, where an action a is chosen from a distribution
is called a deterministic policy
- as opposed to a stochastic policy, where an action a is chosen from a distribution ![]() with probability
with probability ![]() .
.
a a1 a2 a3 Q(x,a) 0 5.1 5Deterministic policy - When in x, always take action a2.
Stochastic policy - When in x, 80 % of time take a2, 20 % of time take a3.
Typically - Start stochastic. Become more deterministic as we learn.
Following a stationary deterministic policy ![]() ,
at time t, the agent observes state
,
at time t, the agent observes state ![]() , takes action
, takes action ![]() ,
observes new state
,
observes new state ![]() , and receives reward
, and receives reward ![]() with expected value:
with expected value:
![]()
Do we go for short-term gain or long-term gain?
Can we take
Short-term loss for Long-term gain?
Instead of deciding here for all problems, we make this a parameter that we can adjust.
Not just maximise immediate E(r) (i.e. simply deal with probability).
Could maximise long-term sum of expected rewards. This may involve taking a short-term loss for long-term gain (equivalent to allowing a move downhill in hill-climbing).
![]()
The discounting factor γ defines how much expected future rewards affect decisions now.
0 ≤ γ < 1
(e.g. γ = 0.9)
If rewards can be positive or negative, R may be a sum of positive and negative terms.
Special case:
γ = 0
Doesn't work:
γ = 1
(see later)
The interesting situation is in the middle (0 < γ < 1)
Genuine immediate reinforcement learning is the special case
r in the future can even override immediate punishment
If we decide what to do based on which path has highest R, then [punishment now, r in the future] can beat [reward now, but not in future] if:
If maximum reward is rmax,
what is maximum possible value of R?
The most it could be would be to get the maximum reward every step:
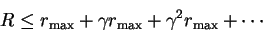
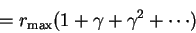
What is this quantity on the right? Let:
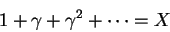
Multiply by γ:
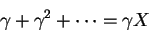
Subtract the 2 equations:
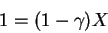
And we get a value for X:
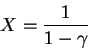
That is:
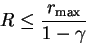
This is just the
Negative Binomial Series
in the
Binomial Theorem.
(x+1)(-1)
= 1 - x + x2 - x3 + x4 - ...
Let x = - γ
The expected total discounted reward
if we follow policy ![]() forever,
starting from
forever,
starting from ![]() , is:
, is:
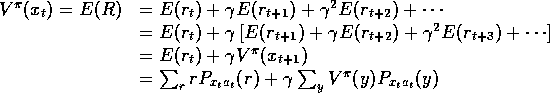
![]() is called the value of state x under policy
is called the value of state x under policy ![]() .
The problem for the agent is to find an optimal policy - one that maximizes the total discounted expected reward
(there may be more than one policy that does this).
.
The problem for the agent is to find an optimal policy - one that maximizes the total discounted expected reward
(there may be more than one policy that does this).
It is known (not shown here) that in an MDP,
there is a stationary and deterministic optimal policy.
Briefly, in an MDP one does not need memory to behave optimally,
the reason being essentially that the current state contains all information about what is going to happen next.
A stationary deterministic optimal policy ![]() satisfies, for all x:
satisfies, for all x:
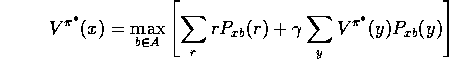
For any state x, there is a unique value ![]() , which is the best that an agent can do from x.
Optimal policies
, which is the best that an agent can do from x.
Optimal policies ![]() may be non-unique, but the value
may be non-unique, but the value ![]() is unique.
All optimal policies
is unique.
All optimal policies ![]() will have:
will have:
![]()
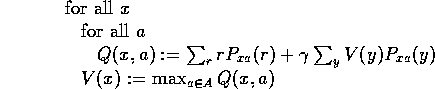
This systematic iterative DP process is obviously an off-line process. The agent must cease interacting with the world while it runs through this loop until a satisfactory policy is found.
Note that initially-random V and Q are on RHS of equation, so updates must be repeated to factor in more accurate values later.
The exception is if
γ = 0
(only look at immediate reward).
Then
you only need one iteration of updates and you are done.
You have worked out immediate E(r) completely.
Fortunately, we can still learn from this. In the DP process above, the updates of V(x) can in fact occur in any order, provided that each x will be visited infinitely often over an infinite run. So we can interleave updates with acting in the world, having a modest amount of computation per timestep. In Q-learning we cannot update directly from the transition probabilities - we can only update from individual experiences.
In the real world, we may not know how to get back to state x
to try another action:
x = "I am at party"
a = "I say chat-up line c1"
result - punishment
I might want to say "Go back to x, try c2" but I may not know how to get back to x. All I can do is try out actions in the states in which I happen to find myself. I have to wait until state x happens to present itself again.
Q-learning is for when you don't know Pxa(y) and Pxa(r).
But one approach is just:
Interact with world large number of times
to build up a table of estimates for
Pxa(y)
and
Pxa(r).
Then just do offline DP.