Back-propagation is a heuristic
What is Back-propagation doing?
Can Back-propagation guarantee to find an optimal solution?
Can Back-propagation fail?
Hill-climbing/descending
First, consider the
Back-propagation algorithm.
It is based on descending an
Error landscape.
We change the weights according to slope
to reduce the error.
This is Hill-climbing/descending
(aka "gradient descent/ascent").
Notes:
-
If slope is large then our rule causes us to make large jumps
in the direction that seems to be downhill.
- We do not know this will be downhill.
We do not see the whole landscape.
All we do is change the x value and hope the y value is smaller.
It may turn out to have been a jump uphill.
-
As we approach a minimum, the slope must approach zero
and hence we make smaller jumps.
As we get closer to the minimum, the slope is even closer to zero
and so we make even smaller jumps.
Hence the system converges to the minimum.
Change in weights slows down to 0.
-
If slope is zero we do not change the weight.
- As long as slope is not zero
we will keep changing w.
We will never stop until slope is zero.
Multiple descents
- Remember this is just the landscape for this weight.
There are other landscapes for the other weights.
- Also, for this weight, this is just the landscape for this exemplar.
On the next time step we will be adjusting this weight
in relation to the error landscape for the next exemplar.
We mix up the exemplars.
Rather than single-mindedly descending one mountain,
we are trying to descend multiple mountains at once.
Different weights do eventually
end up specialised on different zones of the input space,
i.e. specialised on one particular descent
(or rather a family of similar descents).
But this takes time.
At the start, things are much more noisy.
See How does specialisation happen?
- Since all the other weights are constantly changing,
even next time round the same exemplar is shown to the same weight,
the error landscape will be different.
- We don't actually have an equation for the landscape.
All we have is a single point on the x axis
and a corresponding value for E and the slope
(at this point only).
We have to make a decision based on this.
Next time round there will be a different landscape
and a different point.
What is also often done is that the learning rate C starts high
and declines as learning goes on.
With single-layer networks, for a function that is linearly separable,
where we know that some configuration of the network
can separate them,
there can be a
Convergence Proof,
in the sense that we can prove that
the network will learn to separate the exemplars.
For a multi-layer net, what does a
Convergence Proof mean?
That we can approximate the function f?
To what level of accuracy?
Anyway, which function?
A more complex function requires a larger network.
Maybe with the current network architecture
we can only represent f crudely.
Convergence Proof could prove that it converges to something,
i.e. stops changing.
But perhaps to local optimum
rather than global optimum.
Summary:
Back-prop is a heuristic.
It cannot guarantee to find the globally optimal solution.
The following reading explains the nature of back-propagation.
- Rumelhart et al - Defines back-prop as a heuristic.
- Kolen and Pollack - Considers what solution (of many) the heuristic will find.
- "Back Propagation is Sensitive to Initial Conditions".
Kolen, J. F. and Pollack, J. B. (1990).
Complex Systems, 4,3, 269-280.
- They sum it up:
"Rumelhart et al. made a confident statement: for many tasks,
"the network rarely gets
stuck in poor local minima that are significantly worse
than the global minima." ...
The convergence claim was based solely upon their empirical experience with the back
propagation technique. Since then, Minsky and Papert ... have argued that there exists no
proof of convergence for the technique, and several researchers ... have found that the convergence time must be related to the difficulty of the
problem, otherwise an unsolved computer science question (P=NP) would finally be answered.
We do not wish to make claims about convergence of the technique in the limit (with vanishing
step-size), or the relationship between task and performance, but wish to talk about a pervasive
behavior of the technique which has gone unnoticed for several years: the sensitivity of back
propagation to initial conditions."
- They point out that, as a heuristic,
it will find some local optimum.
Given the same training set,
which local optimum it finds
is decided entirely by the initial
weights.
Note on search for weights
- We cannot guarantee to find the global optimal set of weights.
-
We could in theory ignore
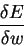 and
search for the correct network
by doing an exhaustive search on all
sets of weights.
and
search for the correct network
by doing an exhaustive search on all
sets of weights.
- But search space is too big.
-
The initial (random) weights and
constrain our search
to make it practical.
But does so by limiting
from the start the solutions
we will find.
- Pollack - Says a heuristic approach is normal.
- "No Harm Intended: A Review of the Perceptrons expanded edition".
Pollack, J. B. (1989).
Journal of Mathematical Psychology, 33, 3, 358-365.
- He points out that this is just normal in AI
(to have a heuristic that cannot search the whole space):
"Minsky and Papert point out, rightly, that Rumelhart et al have no result,
like the
Perceptron Convergence Theorem ... that the generalized delta rule is
guaranteed to find solutions when they exist, and that "little has been proved about the
range of problems upon which [the generalized delta rule] works both efficiently and
dependably." ...
On the other hand, we also know that for certain classes of very hard problems,
there are no algorithms which scale significantly better than exhaustive search, unless
they are approximations. But there are many such impractical and approximate methods
which are in practical use worldwide. Despite the fact that the Traveling Salesman Problem
is NP-complete, salespersons do travel, and often optimally."
- 1950s-60s
- Learning rules for single-layer nets.
Also interesting to note that HLLs primitive or non-existent.
Computer models often focused on raw hardware/brain/network models.
-
1969
- Perceptrons, Minsky and Papert.
Limitations of single-layer nets apparent.
People (in fact, Minsky and Papert themselves!)
were aware that multi-layer nets
could perform more complex classifications.
That was not the problem.
The problem was the absence of a learning rule
for multi-layer nets.
Meanwhile, HLLs had been invented,
and people were excited about them,
seeing them as possibly the language of the mind.
Connectionism went into decline.
Explicit, symbolic approaches dominant in AI. Logic. HLLs.
-
1974
- Back-propagation (learning rule for multi-layer) invented
by Werbos,
but not noticed.
-
1986
- Back-prop popularised.
Connectionism takes off again.
Also HLLs no longer so exciting.
Seen as part of Computer Engineering, little to do with brain.
Increased interest in numeric and statistical models.