Learning rate that does not start at 1
Recall
convergence conditions.
The typical 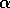 goes from 1 down to 0,
but note that if the conditions hold, then for any t,
goes from 1 down to 0,
but note that if the conditions hold, then for any t,
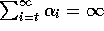 and
and
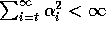 ,
so may start anywhere along the sequence.
That is, may take successive values
,
so may start anywhere along the sequence.
That is, may take successive values 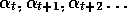
Q-learning will forget bad samples at the start
To "forget" old stuff, you could reset
α = 1.
But in fact you don't have to:
α
may start anywhere along the sequence
and conditions for convergence satisfied.
So can just keep learning and old stuff is eventually wiped.
e.g. Say world changes from
MDP1 to MDP2 after time t.
Just keep going with Q-learning
and will learn optimal policy for MDP2
(eventually)
and will forget what it learnt for MDP1
(eventually).
No need to change anything.
Q-learning automatically adapts if world/problem changes.
Starting α at 1/t
Recall our
running average.
Let 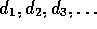 be samples of a stationary random variable d
with expected value E(d).
Repeat:
be samples of a stationary random variable d
with expected value E(d).
Repeat:
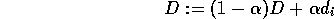
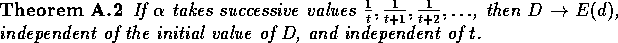
Proof:
D's updates go:
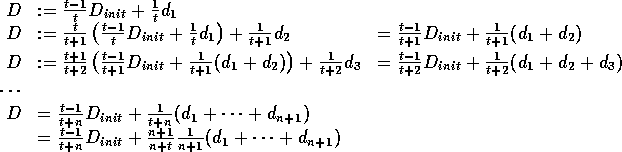
As 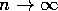 :
:

that is,
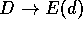 .
.

One way of looking at this
is to consider 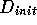 as the average of all samples before time t,
samples which are now irrelevant for some reason.
We can consider them as samples from a different distribution f:
as the average of all samples before time t,
samples which are now irrelevant for some reason.
We can consider them as samples from a different distribution f:
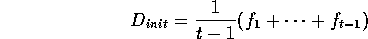
Hence:
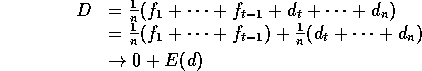
as .
Because:
1/n ( dt + ... + dn )
= (n-t+1)/n 1/(n-t+1) ( dt + ... + dn )
-> 1 . E(d)
Initial bias
If start at:
α = 1/t
then initial Q-values bias our Q-values for some time.
And since we only run for finite time in any finite experiment,
the bias may still be there after learning.
Consider being "born" with Q-values already filled in (i.e. in DNA)
and then start learning:
- Lamarckism:
- Not-quite Lamarckism:
The Baldwin Effect
- Baldwin
-
The Baldwin Effect
(and here)
- Evolution and learning can look like Lamarckian inheritance.
We don't have infinite time to learn.
It's easier to learn the optimal policy in your finite lifespan
if you are born close to it to begin with.
- The original paper:
"A New Factor in Evolution",
James Mark Baldwin,
American Naturalist, 1896.
- Example of being "born" with Q-values:
x = at cliff edge
a1 = go forward
a2 = go back
bad Q-values to be born with:
a1 a2
Q(x,a) 0 0
good Q-values to be born with:
a1 a2
Q(x,a) -1000 0
- even if experiment in childhood,
with a moderate temperature
Boltzmann control policy,
still unlikely to try a1.
Not-quite Lamarckism in nature
-
Gunnar Kaati's work on
diet affecting genes
in the next two generations.
(Possibly choosing from pre-selected pool,
turning genes for famine/plenty on and off.)
- It is long established that pregnant mother's lifestyle
influences development of fetus.
Mother's diet, stress,
alcohol,
influence baby's development. (And genes?)
-
Robert Pruitt's work
on plants being able to reconstruct genes from their ancestors
that they strictly speaking did not inherit from their parents.
i.e. Plant considers its own DNA unsatisfactory, and changes it.
- Epigenetics
-
Epigenetics: Genome, Meet Your Environment
by Leslie A. Pray -
"As the evidence accumulates for epigenetics, researchers reacquire a taste for Lamarckism"