![]()
![]()
Proof: D's updates go:
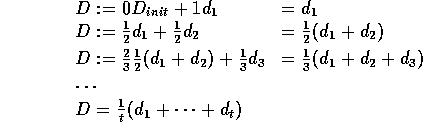
i.e. D is simply the average of all ![]() samples so far.
samples so far.
As ![]() ,
,
![]() .
.
![]()
![]()
Proof: D's updates go:
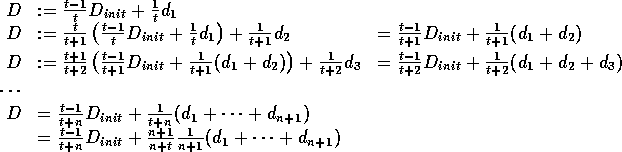
As ![]() :
:
![]()
that is,
![]() .
.
![]()
One way of looking at this
is to consider ![]() as the average of all samples before time t,
samples which are now irrelevant for some reason.
We can consider them as samples from a different distribution f:
as the average of all samples before time t,
samples which are now irrelevant for some reason.
We can consider them as samples from a different distribution f:
![]()
Hence:
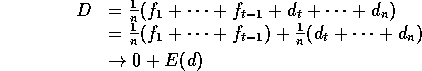
as ![]() .
.
An alternative approach (e.g. see [Grefenstette, 1992]) is to build up not the average
of all samples, but a time-weighted sum of them,
giving more weight to the most recent ones.
This is accomplished by setting ![]() to be constant,
in which case D's updates go:
to be constant,
in which case D's updates go:
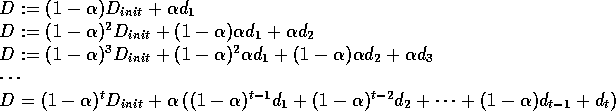
Since ![]() as
as ![]() ,
this weights more recent samples higher.
Grefenstette uses typically
,
this weights more recent samples higher.
Grefenstette uses typically ![]() .
.
Consider sampling alternately from two stationary random variables d and f:
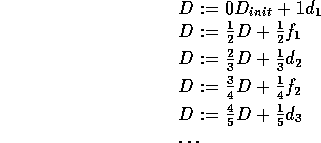
![]()
Proof: From Theorem A.1, after 2t samples:
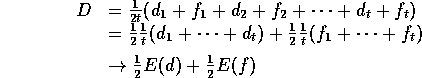
as ![]() .
.
![]()
More generally,
consider where we have multiple stationary distributions ![]() ,
where each distribution
,
where each distribution ![]() has expected value
has expected value ![]() .
At each time t, we take a sample
.
At each time t, we take a sample ![]() from one of the distributions.
Each distribution
from one of the distributions.
Each distribution ![]() has probability p(i) of being picked.
Repeat:
has probability p(i) of being picked.
Repeat:
![]()
![]()
Proof:
For a large number of samples t
we expect to take p(1) t samples from ![]() ,
p(2) t samples from
,
p(2) t samples from ![]() ,
and so on.
From Theorem A.1, we expect:
,
and so on.
From Theorem A.1, we expect:
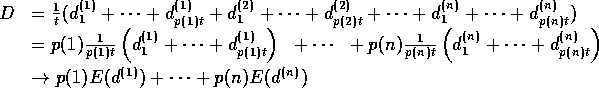
as ![]() .
.
![]()
Return to Contents page.