wherereward: if (best event)
else if (good event)
else
(x,a) leads to sequenceand then
forever
(x,b) leads to sequence
and then
Currently action b is the best.
We lose ![]() on the fifth step certainly,
but we make up for it by receiving the payoff from
on the fifth step certainly,
but we make up for it by receiving the payoff from ![]() in the first four steps.
However, if we start to increase the size of
in the first four steps.
However, if we start to increase the size of ![]() , while keeping
, while keeping ![]() and
and ![]() the same,
we can eventually make action a the most profitable path to follow
and cause a switch in policy.
the same,
we can eventually make action a the most profitable path to follow
and cause a switch in policy.
Increasing the difference between its rewards may cause ![]() to have new disagreements, and maybe new agreements,
with the other agents about what action to take,
so the progress of the W-competition may be radically different.
Once a W-value changes, we have to follow the whole re-organisation
to its conclusion.
to have new disagreements, and maybe new agreements,
with the other agents about what action to take,
so the progress of the W-competition may be radically different.
Once a W-value changes, we have to follow the whole re-organisation
to its conclusion.
What we can say is that multiplying all rewards by the same constant (see §D.4 shortly), and hence multiplying all Q-values by the constant, will increase or decrease the size of all W-values without changing the policy.
The normalised agent will have the same policy and the same W-values.
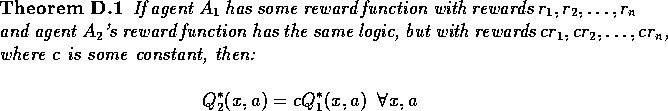
Think of it as changing the "unit of measurement" of the rewards.
Proof:
When we take action a in state x,
let ![]() be the probability that reward
be the probability that reward ![]() is given to
is given to ![]() (and therefore that reward
(and therefore that reward ![]() is given to
is given to ![]() ).
Then
).
Then ![]() 's expected reward is simply c times
's expected reward is simply c times ![]() 's expected reward:
's expected reward:
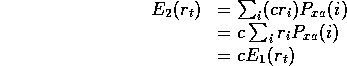
It follows from the definitions in §2.1 that
![]() and
and
![]() .
.
![]()
![]() I should note this only works if:
c
> 0
I should note this only works if:
c
> 0
![]() will have the same policy as
will have the same policy as ![]() ,
but larger or smaller W-values.
,
but larger or smaller W-values.
Return to Contents page.