where r > s.reward: if (good event) r else s
Proof: Let us fix r and s and learn the Q-values. In a deterministic world, given a state x, the Q-value for action a will be:
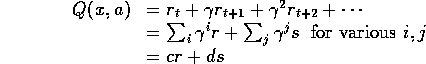
for some real numbers ![]() .
The Q-value for a different action b will be:
.
The Q-value for a different action b will be:
![]()
where ![]() .
That is, e + f = c + d .
.
That is, e + f = c + d .
So whichever one of c and e is bigger defines which is the best action
(which gets the larger amount of the "good" reward r),
irrespective of the sizes of r > s.
![]()
Note that these numbers are not integers - it may not be simply a question of the worse action receiving s instead of r a finite number of times. The worse action may also receive r instead of s at some points, and also the number of differences may in fact not be finite.
To be precise, noting that (c-e) = (f-d) , the difference between the Q-values is:
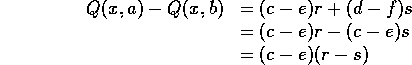
where the real number (c-e) is constant for the given two actions a and b in state x. (c-e) depends only on the probabilities of events happening, not on the specific values of the rewards r and s that we hand out when they do. Changing the relative sizes of the rewards r > s can only change the magnitude of the difference between the Q-values, but not the sign. The ranking of actions will stay the same.
For example, an agent with rewards (10,9) and an agent with rewards (10,0)
will have different Q-values
but will still suggest the same optimal action ![]() .
.
In a probabilistic world, we would have:
![]()
where p + q = 1 , and:
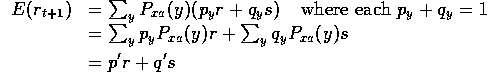
for some p' + q' = 1 .
| E(rt+1) | = Σ y Pxa(y) r(x,y) |
| = Pxa(y1) r(x,y1) + ... + Pxa(yn) r(x,yn) | |
| = p' r + q' s |
Hence:
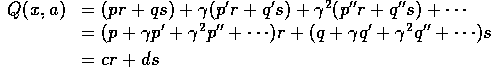
for some ![]() as before.
as before.
Proof: From the proof of Theorem C.1:
![]()
where ![]() is a constant independent of the particular rewards.
is a constant independent of the particular rewards.
![]()
Using our "deviation" definition, for the 2-reward agent in a deterministic world:
![]()
The size of the W-value that ![]() presents in state x if
presents in state x if ![]() is the leader
is simply proportional to the difference between its rewards.
If
is the leader
is simply proportional to the difference between its rewards.
If ![]() wants to take the same action as
wants to take the same action as ![]() ,
then
,
then ![]() (that is, (c-e) = 0).
If the leader switches to
(that is, (c-e) = 0).
If the leader switches to ![]() , the constant switches to
, the constant switches to ![]() .
.
Increasing the difference between its rewards will cause ![]() to have the same disagreements with the other agents about what action to take,
but higher
to have the same disagreements with the other agents about what action to take,
but higher ![]() values
- that is, an increased ability to compete.
So the progress of the W-competition will be different.
values
- that is, an increased ability to compete.
So the progress of the W-competition will be different.
For example, an agent with rewards (8,5) will be stronger (will have higher W-values and win more competitions) than an agent with the same logic and rewards (2,0). And an agent with rewards (2,0) will be stronger than one with rewards (10,9). In particular, the strongest possible 2-reward agent is:
else

From Theorem C.1, this will have different Q-values but the same Q-learning policy. And from Theorem C.2, it will have identical W-values. You can regard the original agent as an (r-s), 0 agent which also picks up an automatic bonus of s every step no matter what it does. Its Q-values can be obtained by simply adding the following to each of the Q-values of the (r-s), 0 agent:
![]()
We are shifting the same contour up and down the y-axis in Figure 8.1.
The same suggested action and the same W-values means that for the purposes of W-learning it is the same agent. For example, an agent with rewards (1.5,1.1) is identical in W-learning to one with rewards (0.4,0). The W=Q method would treat them differently.
where r > 0 .reward: if (good event) r else 0
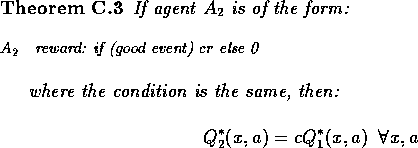
Proof:
We have just multiplied all rewards by c,
so all Q-values are multiplied by c.
If this is not clear, see the general proof
Theorem D.1.
![]()
![]() I should note this only works if:
c
> 0
I should note this only works if:
c
> 0
![]() will have the same policy as
will have the same policy as ![]() ,
but different W-values.
We are exaggerating or levelling out the contour
in Figure 8.1.
In particular, the strongest possible normalised agent is:
,
but different W-values.
We are exaggerating or levelling out the contour
in Figure 8.1.
In particular, the strongest possible normalised agent is:
Return to Contents page.