Instead of supervised learning (exemplars), we don't tell it correct "class" / action. Instead we give sporadic indirect feedback (a bit like "this classification was good/bad").
e.g. Move your muscles to play basketball. I can't articulate what instructions to send to your muscles / robot motors and in what order. But a child could sit there and tell you when you have scored a basket. In fact, even a machine could detect and automatically reward you when a basket is scored.
Robot playing
air hockey
by Reinforcement Learning.
2006 video.
See paper,
Humanoid Robot Learning and Game Playing Using PC-Based Vision,
by
Darrin C. Bentivegna et al,
in Proceedings of the 2002 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2002), Switzerland, 2002.
Translated into the terms we will be using:
Already we see typical things:
If tried out every possible action in every possible state, 4200 experiments to carry out.
Build model of Physics.
Take distance (p - junction)
Time for car to cover distance given speed s
Time it takes agent to cross road
Problems / Restrictions:
Look at consequences of actions.
"Let the world be its own model"
If action a worked, keep it.
If not, explore other action a2.
After many iterations, we learn the correct action patterns
to any level of granularity.
And we never had to understand how the world worked!
We learn the mapping:
x, a -> y
initial state, action -> new state
If one can do exhaustive search, you don't need RL or any complex learning.
More usual: Only have time to try some actions in some states.
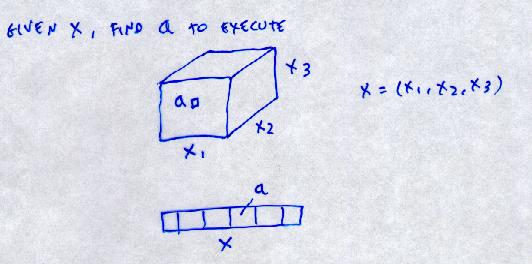
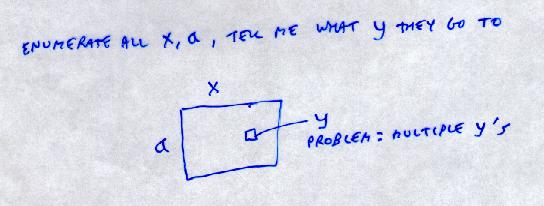
Multiple y's:
e.g. If you are in state x and take action a
50% of the time you will end up in state y1
and 50% of the time you will end up in state y2
e.g. x = (7,5)
a = (1,5)
y1 = (6,5)
y2 = (7,5)
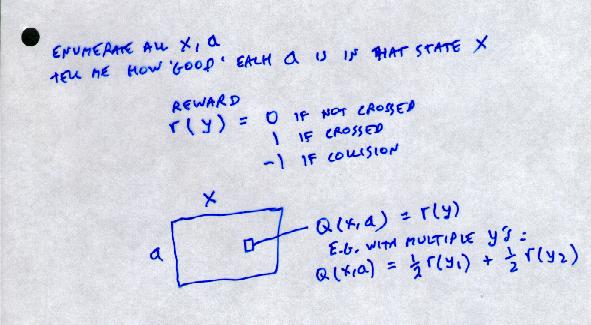
Whereas adding states is meaningless:
"Expected next state = ½ (y1 + y2)"
In example above,
½ (y1 + y2) = (6 ½, 5)
Expected state?
If you take action a, do you ever go to this state?
Does this state even exist?
Machine writes a program x -> a only if we can think of a program that will write this program.
This may require restricting the domain. e.g. Below we will restrict ourselves to writing a stimulus-response program - well-understood model, our program will provably write an optimal solution.
Genetic Programming is a program to write any general-purpose program - Too far too fast?
Robot learning to flip pancakes by RL.
From Petar Kormushev.
2010 video.
Google DeepMind's
Deep Q-learning (RL) playing Atari Breakout.
2015 video.
AI Learns to Escape Extreme Maze (using Deep Reinforcement Learning).
From AI Warehouse.
2025 video.
Robot learning to walk in real world (not from simulation).
2022 video.
See paper:
DayDreamer: World Models for Physical Robot Learning, by Philipp Wu et al, 2022.
Core issue:
"Deep reinforcement learning is a common approach to robot learning
but requires a large amount of trial and error to learn, limiting its deployment in
the physical world. As a consequence, many advances in robot learning rely on
simulators. On the other hand, learning inside of simulators fails to capture the
complexity of the real world, is prone to simulator inaccuracies, and the resulting
behaviors do not adapt to changes in the world."
Their key is learning a world model.