Q-learning with a Neural Network:
Input x,a.
Output yk = Q(x,a).
We are not learning from correct exemplars, as in normal supervised learning. That would be like being given the "correct" output:
Instead we are learning from estimates. The output we are "moving towards" is:
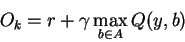
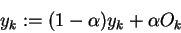
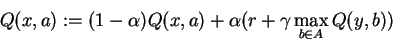
But of course the term:
is just an estimate, and Q itself is changing
as we go along.
The "timeless" information is that x,a led to y,r. We can save these 4 values and "replay" the experience many times, with improved values of Q.
Read discussion of replay.
There are lots of interesting issues. For example, replay:
(x,a) -> (y,r)a million times and it learns that all (x,a) lead to (y,r). We need to mix up our replays. Remember our discussion of over-learning and forgetting.
Also random learning, which worked with lookup tables, won't work with neural nets, because the exemplars interfere with each other. The net will just learn that all actions lead to nothing. We will need a more intelligent control policy, something like a Boltzmann distribution.