we build up estimates of Q(x,a) = how good action a is in state x start with Q(x,a) random or zero do for a long time { observe x suggest a according to some algorithm execute a observe y receive reward r(y) or r(x,y) modify Q(x,a) according to some algorithm }
a can be "no-op".
Note that having a reward every time step is actually no restriction. The classic delayed reinforcement problem is just a special case with, say, most rewards zero, and only a small number of infrequent rewards non-zero.
The agent observes discrete states of the world x ( ![]() , a finite set)
and can execute discrete actions a (
, a finite set)
and can execute discrete actions a ( ![]() , a finite set).
Each discrete time step, the agent observes state x, takes action a,
observes new state y, and receives immediate reward r.
, a finite set).
Each discrete time step, the agent observes state x, takes action a,
observes new state y, and receives immediate reward r.
Transitions are probabilistic,
that is, y and r are drawn from stationary probability distributions ![]() and
and ![]() , where
, where
![]() is the probability that taking action a in state x will lead to state y
and
is the probability that taking action a in state x will lead to state y
and ![]() is the probability that taking action a in state x will generate reward r.
We have
is the probability that taking action a in state x will generate reward r.
We have ![]() and
and ![]() .
.
Start in state x:
In state x,
taking action b gives a guaranteed reward of 1.5.
Taking action a normally leads to a reward of only 1,
but sometimes leads to a reward of 5.
Pxa(y) = 0.8
Pxa(z) = 0.2
Pxa(w) = 0 for all w other than y,z
(probabilistic transition)
Pxb(s) = 1
Pxb(w) = 0 for all w other than s
(deterministic transition)
![]()
and the stationary property is expressed as:
![]()
Probabilistic transitions ![]() .
.
In fact the world above is not exactly an MDP.
Consider:
P ( xt+1=bump |
xt=st, at=bt,
xt-1=st-1, at-1=bt-1,
... )
P ( bump | wall is N, move N, wall is N, move N, wall is N, move N )
is higher than:
P ( bump | wall is N, move N, wall not visible, move N, wall not visible, move N )
i.e. There isn't simply a constant:
P ( bump | wall is N, move N )
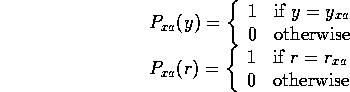
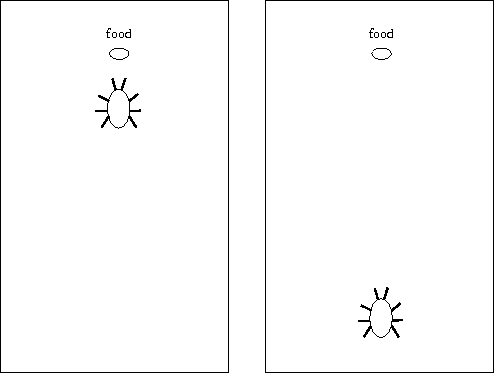
Observe x Take a (Opponent makes non-deterministic move) Observe y
The set of actions available may differ from state to state. Depending on what we mean by this, this may also possibly be represented within the model, as the special case of an action that when executed (in this particular state, not in general) does nothing:
![]()
for all actions a in the "unavailable" set for x .
Note this would not exactly be "do nothing" since you would still get the reward for staying in x. It could therefore be a useful action!
In this:
![]()
How do we decide which action to take?
Look at expected reward:
Ea(r) = 0.2 (5) + 0.8 (1)
= 1.8
Eb(r) = 1 (1.5)
= 1.5
Action a is better.
What do the probabilities mean?
They mean that if you take a 100 times,
you expect 20 5's and 80 1's.
Total reward 180.
If you take b 100 times
you expect 100 1.5's.
Total reward 150.
Maximise E(r).
When we take action a in state x, the reward we expect to receive is:
![]()
E(r) = p1 r1 + ... + pn rn
≥ p1 rmin + ... + pn rmin
= 1 . rmin
You are in state x = (1,5).
Imagine that if you take some action a,
you go to state y with
probabilities:
You can calculate E(r).y Pxa(y) reward (1,8) 0.4 10 (0,8) 0.3 5 (1,5) 0.2 1 (0,5) 0.1 0
But "E(y)" is meaningless.
Consider the sum of the y's times their probabilities
= (1,8) 0.4 + (0,8) 0.3 + (1,5) 0.2 + (0,5) 0.1
= (0.6, 7.1)
You are never in this state when you take a.
In fact, this state doesn't exist.
"0.6" doesn't have a meaning.
The state space is not a continuous space. It is a discrete space of points.
Typically, we don't reward for the correct action, r = r(x,a):
in state x if took action b then reward 1 else reward 0because we don't know the correct action! That's why we're learning.
in state x if got to state z then reward 1 else reward 0
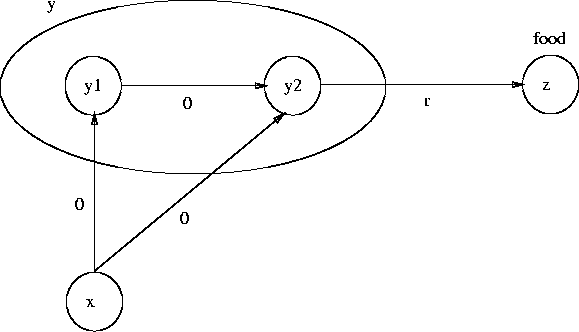
Writing r = r(x,y), the probability of a particular reward r is:
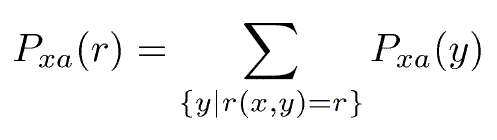
and the expected reward becomes:
![]()
That is, normally we never think in terms of ![]() - we only think in terms of
- we only think in terms of ![]() .
.
e.g. In the following:
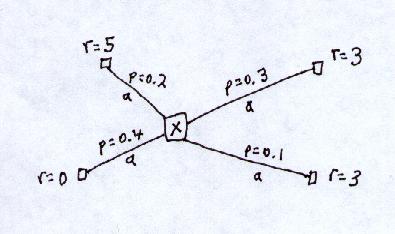
Taking action a in state x,
P(r=5) = 0.2
P(r=0) = 0.4
P(r=3) = 0.3 + 0.1
= 0.4
Question - What is E(r)?
In some models, rewards are associated with states, rather than with transitions, that is, r = r(y). The agent is not just rewarded for arriving at state y - it is also rewarded continually for remaining in state y. This is obviously just a special case of r = r(x,y) with:
![]()
and hence:
![]()
Reward on transition to good state only: r = r(x,y).
e.g. x = not at waterhole, y = at waterhole.
Problem - may leave state to come back in!
Reward for arriving and staying in good state: r = r(y).