Now we return to the House Robot problem to test W-learning. There being no global (x,i) statespace to worry about, we can expand the number of agents. To the previous five we add three more agents. The collection of agents is as follows:

Rewards are in the range ![]() .
Both the
.
Both the ![]() values and
values and ![]() values refer to x in the subspaces,
for which lookup tables can be used.
values refer to x in the subspaces,
for which lookup tables can be used.
![]() should head for the centre of an open area
while
should head for the centre of an open area
while ![]() should engage in wall-following.
In fact, as we shall see,
should engage in wall-following.
In fact, as we shall see, ![]() turned out to be useless
since its preferred action of course is to stay still.
Perhaps its reward should just have been if (wall visible) ..
turned out to be useless
since its preferred action of course is to stay still.
Perhaps its reward should just have been if (wall visible) ..
We can add more agents than probably needed - if they're not useful they just won't win any W-competitions and won't be expressed. In Hierarchical Q-learning, you can add extra agents that aren't chosen by the switch but you pay the price of a larger (x,i) statespace.
Since the exact values of these rewards ![]() don't matter
for the policy learned by Q-learning,
why do we not set them all to 1 as we did
before?
don't matter
for the policy learned by Q-learning,
why do we not set them all to 1 as we did
before?
The answer is that the size of the rewards affect the size of the W-values. Theorem C.2 shows that if we have an agent of the form:
reward: if (good event) r else s
then ![]() will present W-values:
will present W-values:
![]()
where ![]() is a constant independent of the particular rewards.
W is simply proportional to the subtraction (r-s), so in particular we lose nothing
by fixing s = 0 here and just looking at different
values of r.[1]
Then we have simply:
is a constant independent of the particular rewards.
W is simply proportional to the subtraction (r-s), so in particular we lose nothing
by fixing s = 0 here and just looking at different
values of r.[1]
Then we have simply:
![]()
Increasing the size of ![]() will cause
will cause ![]() to have the same policy
(the same disagreements with the other agents about what action to take),
but higher W-values
(an increased ability to compete).
to have the same policy
(the same disagreements with the other agents about what action to take),
but higher W-values
(an increased ability to compete).
![]() is the parameter by which we make agents with the same logic
stronger or weaker within the creature as a whole.
We do not want all agents to be of equal importance within the creature.
Rather, adaptive collections are likely to involve well-chosen combinations of weak and strong agents.
For instance, a creature containing a strong version of the predator-avoiding agent:
(if predator visible r = -10 else r = 0)
will behave differently from one containing a weak version of the same thing:
(if predator visible r = -0.1 else r = 0).
The predator-avoiding agent in both will be suggesting the same actions,
but in the former creature it is more likely to actually win its competitions.
is the parameter by which we make agents with the same logic
stronger or weaker within the creature as a whole.
We do not want all agents to be of equal importance within the creature.
Rather, adaptive collections are likely to involve well-chosen combinations of weak and strong agents.
For instance, a creature containing a strong version of the predator-avoiding agent:
(if predator visible r = -10 else r = 0)
will behave differently from one containing a weak version of the same thing:
(if predator visible r = -0.1 else r = 0).
The predator-avoiding agent in both will be suggesting the same actions,
but in the former creature it is more likely to actually win its competitions.
The set of agents above define a vast range of creature behaviors,
depending on how strong each agent is.
For example, if ![]() and all other rewards are 0.001,
then
and all other rewards are 0.001,
then ![]() will beat all other agents in competition
since its absolute (D-f) differences will be so large compared to theirs.
In almost all states x it will build up a higher W-value
will beat all other agents in competition
since its absolute (D-f) differences will be so large compared to theirs.
In almost all states x it will build up a higher W-value ![]() than any of the competitor
than any of the competitor ![]() 's.
The house robot will be completely dominated by
's.
The house robot will be completely dominated by ![]() , and will spend all its time
wall-following - in fact, spend all its time stationary, with a wall in sight,
since that is
, and will spend all its time
wall-following - in fact, spend all its time stationary, with a wall in sight,
since that is ![]() 's preferred position.
's preferred position.
In conclusion, the kind of scaling we suggested in §5.4 is not of any use to us. We're quite happy to have unequal agents, to use the absolute differences between Q-values, not relative ones. This demands that their Q-values are all judged on the same scale, but this is no restriction - we have to adjust their rewards relative to each other anyway to make an adaptive collection.
So we try out different combinations of the ![]() 's,
either by hand or by an automated search,
looking for adaptive collections.
A trick that was employed to speed up our search
is that we only have to learn the agents' Q-values once at the start.
We learn the Q-values for reward 1:
's,
either by hand or by an automated search,
looking for adaptive collections.
A trick that was employed to speed up our search
is that we only have to learn the agents' Q-values once at the start.
We learn the Q-values for reward 1:
Then to generate the Q-values for this:
we just multiply the base Q-values byelse 0
Figure 8.1 shows how multiplying the base Q-values by a factor does not change the Q-learning policy (the suggested action) but it does change the progress of W-learning (the differences D - f ) by exaggerating (making the agent stronger) or levelling out (making it weaker) the Q-values, while still preserving their basic contour. This trick allows us make agents weaker or stronger without re-learning Q.
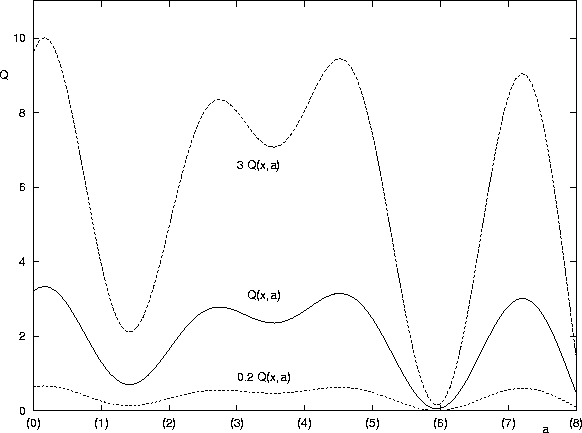
Figure 8.1: Multiplying the reward by a factor multiplies the Q-values by that factor,
which either exaggerates or levels out the contour ![]() .
The agent will still rank the actions in the same order,
and still suggest the same preferred action,
but its W-values will be different.
.
The agent will still rank the actions in the same order,
and still suggest the same preferred action,
but its W-values will be different.
A scaled measure of W, however, would be indifferent to multiplication by a constant.
Say we were using a standard deviation-based measure of W.
Instead of the static, z-score version,
we would probably use a dynamic version depending on ![]() :
:
![]()
Multiplying the base Q-values by a constant c would multiply both the mean and the standard deviation by c. But then our W-value would be:
![]()
that is, unchanged. So we would have no easy way of making agents weaker or stronger. Scaling does not make agents all equal in strength to each other. But the problem is that it makes their inequalities fixed.
Finally, if we can just multiply all the Q-values by a constant,
can't we just multiply the W-values by the constant instead of re-learning them?
The answer is that a W-value depends on who the current leader is.
If we increase ![]() in:
in:
![]()
then ![]() increases, but as soon as it does, everything may change.
increases, but as soon as it does, everything may change.
![]() may go into the lead itself, causing such a huge loss to another agent
that it increases its W-value and then takes over the lead,
and then
may go into the lead itself, causing such a huge loss to another agent
that it increases its W-value and then takes over the lead,
and then ![]() 's W-value will reflect a completely different loss
's W-value will reflect a completely different loss ![]() .
Once a W-value changes, we have to follow the whole re-organisation
to its conclusion.
.
Once a W-value changes, we have to follow the whole re-organisation
to its conclusion.
The agents learn their Q-values from their local reward functions and then organise their action selection by W-learning, all without any reference to the global reward function of §4.3.1. In this work, for purposes of comparison with the other action selection methods, we will now want to test the fitness of the creature.
Obviously, if the global reward function still defines what we are looking for, we still need to use it to score the fitness of the collection. But it no longer need be available to the agents as an explicit function they can learn against. It is only used to test them. Hence the fitness function could be just implicit in the environment, as in the best Artificial Life research [Ray, 1991, Todd et al., 1994].
As has been said many times in contrasting natural evolution with the standard Genetic Algorithm, living things don't have an explicit global reward defined or available to learn from. Their fitness test is only implicit in their environment - whether they manage to live or die. How exactly they replicate is up to them, and what persists over time is often a surprise to the observer.
Similarly, as we give our artificial creature more complex multi-goal tasks, the global reward functions become much harder to design than the local ones (as we argued above).
Imagine that we know what behavior we want when we see it,
but we're having trouble designing a suitable multi-reward global reward function.
So we adopt the strategy of tweaking the ![]() 's by hand,
letting the agents re-organise themselves,
and seeing the result.
Say agent
's by hand,
letting the agents re-organise themselves,
and seeing the result.
Say agent ![]() is not being expressed in the creature's behavior.
We slowly increase
is not being expressed in the creature's behavior.
We slowly increase ![]() until it first starts to win
the one or two absolutely crucial states that it needs.
As we increase
until it first starts to win
the one or two absolutely crucial states that it needs.
As we increase ![]() further, it will win more and more extra states
until eventually it would dominate the creature.
And so on.
further, it will win more and more extra states
until eventually it would dominate the creature.
And so on.
We don't want to design all the explicit behavior, but at the same time we do have some ideas as to what is suitable behavior and what is not, so we do not want to simply design an abstract set of global values as in §4.3.1 and hope for the best. What our decomposition into multiple reward functions defended by competing agents gives us is effectively an adjustable global reward function. We increase the strength in general of particular agents, while still letting the agents sort out the details.
So it would not necessarily be difficult
to design the collection of ![]() 's by hand,
increasing ones that aren't being expressed, and so on.
To test a combination of
's by hand,
increasing ones that aren't being expressed, and so on.
To test a combination of ![]() 's, we multiply the base Q-values by them,
and then re-run the W-competition.
's, we multiply the base Q-values by them,
and then re-run the W-competition.
In fact, in this work I use a simple
Genetic Algorithm
to automate the search.
The genotype encodes a set of ![]() 's
in chromosomes of length 4 (quite a coarse-grained evolutionary search).
We have a population of size 60, initially randomised, evolving for 30 generations.
The advantage of an automated search is that I can be confident
that I have put the same amount of effort into finding good solutions
for each method.
's
in chromosomes of length 4 (quite a coarse-grained evolutionary search).
We have a population of size 60, initially randomised, evolving for 30 generations.
The advantage of an automated search is that I can be confident
that I have put the same amount of effort into finding good solutions
for each method.
For this test (W-learning with subspaces on the House Robot problem)
the best combination of ![]() 's found by GA search was:
's found by GA search was:
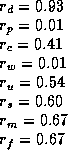
which averages 13.446 per 100 steps, slightly less than we got with Hierarchical Q-learning, but achieved with a reduction in memory requirements from 9.6 million to 1600.
We have solved the problem not with one complex entity, but via the complex interactions of multiple simple entities.
Looking closer at our solution,
note that ![]() , as predicted, is useless.
With such a tiny reward it will not be expressed at all.
Neither, interestingly, will
, as predicted, is useless.
With such a tiny reward it will not be expressed at all.
Neither, interestingly, will ![]() - obviously other agents are managing to take the creature back to the plug often enough for it to not be needed.
The creature as a whole works by interleaving all its goals.
Here are the strongest few W-values:
- obviously other agents are managing to take the creature back to the plug often enough for it to not be needed.
The creature as a whole works by interleaving all its goals.
Here are the strongest few W-values:

We can see that there is a complex intermingling of ![]() ,
, ![]() and
and ![]() .
The states (*,2) (as seen by
.
The states (*,2) (as seen by ![]() ) are those where a human has been identified as a stranger.
These are the crucial states for
) are those where a human has been identified as a stranger.
These are the crucial states for ![]() since it can pick up a continuous reward
if it keeps the human in sight.
The states (*,0) (as seen by
since it can pick up a continuous reward
if it keeps the human in sight.
The states (*,0) (as seen by ![]() ) are those where fire is visible without a wall in the way.
These build up higher W-values (
) are those where fire is visible without a wall in the way.
These build up higher W-values ( ![]() is more confident about what to do)
than when there is a wall in the way,
where
is more confident about what to do)
than when there is a wall in the way,
where ![]() will need some kind of stochastic policy.
will need some kind of stochastic policy.
Here are the probabilities of each action being suggested by ![]() when the fire is in direction 4, behind a wall.
The higher probability actions
under a soft max control policy are highlighted.
when the fire is in direction 4, behind a wall.
The higher probability actions
under a soft max control policy are highlighted.

We can see that ![]() builds up a broad front in approach to the wall.
Moving at right angles to the direction of the fire (directions 2 and 6) is good
because it is more likely to see the end of the wall.
In any case, when the route to the fire is blocked by a wall,
builds up a broad front in approach to the wall.
Moving at right angles to the direction of the fire (directions 2 and 6) is good
because it is more likely to see the end of the wall.
In any case, when the route to the fire is blocked by a wall, ![]() is amenable
to suggestions by other agents, in particular by the combination of
is amenable
to suggestions by other agents, in particular by the combination of ![]() and
and ![]() ,
who drive the house robot in a strong wandering behavior otherwise.
,
who drive the house robot in a strong wandering behavior otherwise.
![]() with its tiny reward is irrelevant - its job is done for it
by
with its tiny reward is irrelevant - its job is done for it
by ![]() bringing the creature towards the centre
and hence quite often past the plug.
bringing the creature towards the centre
and hence quite often past the plug.
![]() has a not insignificant reward, but finds its job is done for it by
has a not insignificant reward, but finds its job is done for it by ![]() ,
which also wants to investigate unidentified humans (in case they turn out to be strangers).
So
,
which also wants to investigate unidentified humans (in case they turn out to be strangers).
So ![]() lets
lets ![]() do all the work for it,
and as long as
do all the work for it,
and as long as ![]() is being obeyed by the creature,
is being obeyed by the creature, ![]() is happy:
is happy:
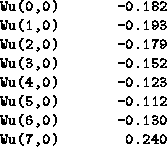
The sole exception is state (7,0), which for some reason fell to ![]() to be responsible for,
while
to be responsible for,
while ![]() took its turn at dropping out of the competition:
took its turn at dropping out of the competition:
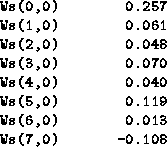
Return to Contents page.