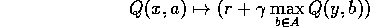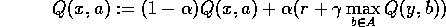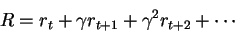
We tend to take the action with the highest Q-value:
maxb Q(x,b)
The Q-value will express the discounted reward if you take that action in that state:
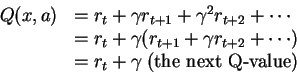
Can be built up recursively:
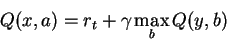
| Q(x,a) := r + γ maxb Q(y,b) |
Problem: We allow a probabilistic world (MDP), where taking the same action a in same state x can have different results.
With the above rule, the Q-value will bounce back and forth:
Q(x,a) := 5
Q(x,a) := 10
Q(x,a) := 6
...
More sensible to build up an average:
Q(x,a) := 5
Q(x,a) := 1/2 (5 + 10)
Q(x,a) := 1/3 (5 + 10 + 6)
...
How do we do this? Do we need an ever-growing memory of all past outcomes?
|
In 1-step Q-learning, after each experience, we observe state y, receive reward r, and update:
(remember notation). The Q-value is updated in the direction of the current sample. Note that we are updating from the current estimate of Q(y,b) - this too is constantly changing. If we store each Q(x,a) explicitly in lookup tables, we update:
|
Since the rewards are bounded, it follows that the Q-values are bounded.

Proof: In the discrete case, Q is updated by:
![]()
so by Theorem B.1:
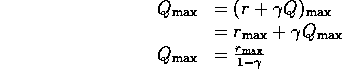
This can also be viewed in terms of temporal discounting:
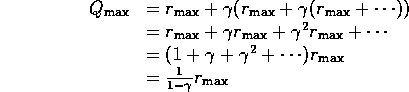
Similarly:
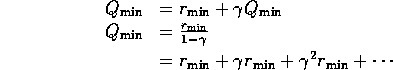
![]()
For example, if ![]() , then
, then ![]() .
And (assuming
.
And (assuming ![]() ) as
) as ![]() ,
, ![]() .
.
Note that since ![]() , it follows that
, it follows that ![]() .
.
i.e. If take this action, you will get immediate reward rmax
and you can get next reward rmax
(it is the best you can get in next state, other actions may be worse)
and you can get next reward rmax ..
....
i.e. If take this action,
you will get immediate reward rmin
and you have to get next reward rmin
(all actions in next state lead to
the worst reward rmin,
otherwise the Q-value would be higher)
and you have to get next reward rmin ..
....
i.e. You are trapped in an attractor
from which you cannot escape.
You cannot ever again get out and go to a state
with rewards greater than rmin (and such states must exist).
Not necessarily a single absorbing state,
but a family of states outside of which you can never leave.
Note if expected reward E(r) = rmin, then you will definitely get rmin on this action (r deterministic, though y can still be probabilistic).