If other agents' actions are meaningless to it, all an agent can do is observe what r and y they generate, as W-learning does. It could perhaps assume that unknown actions have the effect of "do nothing" or "stay still", if they have a Q-value for such an action (§2.1.2), but it might be unwise to assume without observing.
However, if agents share the same suite of actions,
and the other agent's action is recognised by the agent,
it already has built up an estimate
of the expected reward in the value ![]() .
So rather than learning a W-value from samples, it can assign it directly
if the successful action
.
So rather than learning a W-value from samples, it can assign it directly
if the successful action ![]() is communicated to it.
We can do this in the House Robot problem, since all agents share the same suite of actions ("move" 0-8).
In other words, we can follow the walk in §5.6 exactly,
we do not have to approximate it.
is communicated to it.
We can do this in the House Robot problem, since all agents share the same suite of actions ("move" 0-8).
In other words, we can follow the walk in §5.6 exactly,
we do not have to approximate it.
In Negotiated W-learning, the creature observes a state x,
and then its agents engage in repeated rounds of negotiation
before resolving competition and producing a winning action ![]() .
It is obviously to be preferred that the length of this "instant" competition will be very short.
In pseudocode, the Negotiated W-learning method is, each time step:
.
It is obviously to be preferred that the length of this "instant" competition will be very short.
In pseudocode, the Negotiated W-learning method is, each time step:

This algorithm discovers explicitly in one timestep what W-learning only learns over time.
It also gives us the high accuracy of telling states apart, as in W-learning with full statespace, yet without needing to store such a space in memory. In fact its accuracy will be better than W-learning with full statespace since the latter method has to use a generalisation, whereas Negotiated W-learning can tell states apart perfectly. We deal with each full state x as it comes in at run-time. The agents recognise different components of x and compete based on this one-off event.
We have no memory requirements at all for W.
The ![]() are just n temporary variables used at run-time.
In fact, note that "Negotiated W-learning" is actually not learning at all
since nothing permanent is learnt.
are just n temporary variables used at run-time.
In fact, note that "Negotiated W-learning" is actually not learning at all
since nothing permanent is learnt.
The best combination found, scoring 18.212, was:
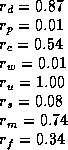
As noted before, the Negotiated W-learning walk may have a different winner depending on which random agent we start the walk going with. Since we run a new competition every timestep, this means that Negotiated W-learning has a stochastic control policy. Note that W-learning may have multiple possible winners too, depending on who takes an early lead. But once a winner is found it has a deterministic control policy.
We could make Negotiated W-learning have a deterministic control policy by recording the winners k(x) for each full state x so that we don't have to run the competition again. On the other hand, we might have dynamic creation and destruction of agents, in which case we would want to re-run the competition every time in case the collection of agents has changed.
Negotiated W-learning could also be used during the learning of Q itself, in which case we will want to re-run the competition each time round with better Q estimates.
Theorem 5.1 shows that the instant competition (or walk through the matrix) is bounded.
To be precise, in the algorithm described above,
the shortest possible loop would be:
Start with random leader.
All other ![]() ,
e.g. all agents agree about what action to take,
,
e.g. all agents agree about what action to take, ![]() .
Loop terminates, length 1.
.
Loop terminates, length 1.
The longest possible loop would be:
Start with random leader, whose W-value is zero.
Some other agent has ![]() and takes the lead.
Try out all other agents,
only to come back to the original leader, whose W-value is now non-zero,
and it wins.
We tried out the original agent, then (n-1) other agents, then the original agent again.
Total length (n+1).
and takes the lead.
Try out all other agents,
only to come back to the original leader, whose W-value is now non-zero,
and it wins.
We tried out the original agent, then (n-1) other agents, then the original agent again.
Total length (n+1).
So the competition length is bounded by 1 and (n+1). Here n = 8 so competitions will be of length 1 to 9. With the combination above, the competition lengths seen over a run of 40000 steps[1] were:
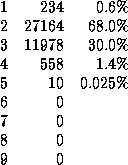
This gives a (reasonably reactive) average competition length of 2.3, as illustrated in Figure 11.1.

Figure 11.1: The "reactiveness" of Negotiated W-learning.
This is a typical snapshot of 200 timesteps,
showing how long it took to resolve competition at each timestep.
The theoretical maximum competition length here is 9.
Figure 11.1 also gives us some idea of how quickly our original method of W-learning actually gets down to a competition between only one or two agents.
Return to Contents page.