A further reason why W-learning underperformed
is that we still haven't found the ideal version of W-learning.
Remember
that using only subspaces for ![]() results in a loss of accuracy.
Using the full space for
results in a loss of accuracy.
Using the full space for ![]() would result in a more sophisticated competition.
would result in a more sophisticated competition.
Consider the competition between the dirt-seeker ![]() and the smoke-seeker
and the smoke-seeker ![]() .
For simplicity, let the global state be x = (d,f).
.
For simplicity, let the global state be x = (d,f).
![]() sees only states (d), and
sees only states (d), and ![]() sees only (f).
When the full state is x = (d,5),
sees only (f).
When the full state is x = (d,5), ![]() simply sees all these as state (5),
that is, smoke is in direction 5.
Sometimes
simply sees all these as state (5),
that is, smoke is in direction 5.
Sometimes ![]() opposes it, and sometimes, for no apparent reason, it doesn't.
But
opposes it, and sometimes, for no apparent reason, it doesn't.
But ![]() averages all these together into one variable.
It is a crude form of competition,
since
averages all these together into one variable.
It is a crude form of competition,
since ![]() must present the same W-value
in many different situations where its competition will want to do quite different things.
The agents might be better able to exploit their opportunities
if they could tell the real states apart
and present different W-values in each one.
must present the same W-value
in many different situations where its competition will want to do quite different things.
The agents might be better able to exploit their opportunities
if they could tell the real states apart
and present different W-values in each one.
If we are to make the x in the ![]() refer to the full state,
then each agent needs a single neural network to implement the function.
The agent's neural network takes a vector input x and produces a floating point output
refer to the full state,
then each agent needs a single neural network to implement the function.
The agent's neural network takes a vector input x and produces a floating point output ![]() .
The Q-values can remain as subspaces of course.
We are back basically to the same memory requirements as Hierarchical Q-learning
- subspaces for the Q-values and then n times the full state x.
.
The Q-values can remain as subspaces of course.
We are back basically to the same memory requirements as Hierarchical Q-learning
- subspaces for the Q-values and then n times the full state x.
Recall that if the winner is to be the strict highest W
we start with W random negative,
and have the leading ![]() unchanged, waiting to be overtaken.
This works for lookup tables,
but will not work with neural networks.
First because trying to initialise W to random negative is pointless
since the network's values will make large jumps up and down in the early stages when its weights are untuned.
Second because even if we do not update it,
unchanged, waiting to be overtaken.
This works for lookup tables,
but will not work with neural networks.
First because trying to initialise W to random negative is pointless
since the network's values will make large jumps up and down in the early stages when its weights are untuned.
Second because even if we do not update it, ![]() will still change as the other
will still change as the other ![]() change.
And if the net doesn't see
change.
And if the net doesn't see ![]() for a while, it will forget it.
for a while, it will forget it.
We could think of various methods to try to repeatedly clamp ![]() ,
but it seems all would need extra memory to remember what value it should be clamped to.
,
but it seems all would need extra memory to remember what value it should be clamped to.
The approach we took instead was:
Start with W random.
Do one run of 30000 steps with random winners
so that everyone experiences what it's like to lose,
and remembers these experiences.
Then they each replay their experiences 10 times to learn from them properly.
Note that when learning W-values in a neural network,
we are just doing updates of the form ![]() .
No W-value is referenced on the right-hand side, unlike the case of learning the Q-values.
Hence there is no need for our concept of backward replay.
.
No W-value is referenced on the right-hand side, unlike the case of learning the Q-values.
Hence there is no need for our concept of backward replay.
With a similar neural network architecture as before, the best combination of agents found, scoring 14.871, was:
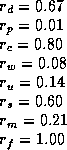
which is better than W-learning with subspaces,
but still not as good as W=Q.
A problem with this method of random winners is that it will actually build up each ![]() to be the average loss over all other agents in the lead:
to be the average loss over all other agents in the lead:
![]()
for ![]() .
So what we are doing is in fact finding:
.
So what we are doing is in fact finding:
![]()
This sum doesn't really mean anything. For example, it is certainly not the loss that the current leader is causing for the agent.
Using random winners is equivalent to a stochastic highest W strategy with fixed high temperature. We would probably have got better results if we had used a more normal stochastic highest W - one with a declining temperature. This would have multiple trials, replay after each trial, and a declining temperature over time as in §4.3.2. But we have some confirmation that telling states apart is a good thing. In the next section, we find out what happens when we can tell states apart perfectly.
Return to Contents page.