The consensus of the last few chapters is that a Minimize the Worst Unhappiness approach is expected to be a better Action Selection strategy than either Maximize the Best Happiness or a Collective method. But we mentioned that we may not yet have found our ideal Minimize the Worst Unhappiness method.
Consider why W-learning approximates a walk through the matrix rather than a global decision. In W-learning, agents don't share the same actions, so they can only see how bad things are by trying them out. It's impractical to let every agent experience what it is like when every other is in the lead, and experience it for long enough to build up the expected loss. W-learning gets down to a winner a lot quicker by just putting someone in the lead and leaving it up to the others to overtake.
Negotiated W-learning concentrates on copying W-learning in one timestep.
But once we share common actions, and we can draw up the matrix, we can do anything.
So let us return to that question of §5.6:
Given a ![]() matrix, who should win?
matrix, who should win?
For example, should we search for the highest ![]() in the matrix?
Should we search for the worst any agent could possibly suffer
and then let that agent win in case it does.
For example, here agents
in the matrix?
Should we search for the worst any agent could possibly suffer
and then let that agent win in case it does.
For example, here agents ![]() or
or ![]() would always win to prevent the other one winning (and loss of 1):
would always win to prevent the other one winning (and loss of 1):
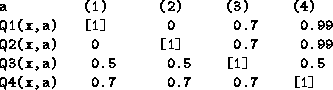
But consider what happens with the W-learning walk.
Say we start with ![]() in the lead.
in the lead.
![]() is suffering 0.5, and goes into the lead with
is suffering 0.5, and goes into the lead with ![]() .
All other agents are now suffering 0.3, so
.
All other agents are now suffering 0.3, so
![]() wins.[1]
Agents
wins.[1]
Agents ![]() and
and ![]() never got to experience each other's disasters since neither ever tried out the lead.
The other agents gave them a way of avoiding each other.
Of course, here the outcome of the walk depends on which random agent we start with.
If we did start with
never got to experience each other's disasters since neither ever tried out the lead.
The other agents gave them a way of avoiding each other.
Of course, here the outcome of the walk depends on which random agent we start with.
If we did start with ![]() or
or ![]() then we would get a straight competition between them.
then we would get a straight competition between them.
So searching for the worst ![]() is a pessimistic method.
W-learning checks whether these hypothetical
is a pessimistic method.
W-learning checks whether these hypothetical ![]() will actually come to pass.
Instead of asking what is the worst deviation an agent could possibly suffer,
W-learning asks what it is likely to suffer if it does not win.
We don't want to be afraid of an event that is not going to happen.
will actually come to pass.
Instead of asking what is the worst deviation an agent could possibly suffer,
W-learning asks what it is likely to suffer if it does not win.
We don't want to be afraid of an event that is not going to happen.
So what should our global decision be? How about instead of starting the walk with a random action, start with the action that satisfies Maximize Collective Happiness and let W-learning run from there. But this doesn't help because W-learning will (almost) always switch from the initial leader who has W = 0 . So how about we look into the future before we switch. Start with the action that satisfies Maximize Collective Happiness and only switch if the agent currently suffers a loss bigger than any it will cause when it gets the lead. That is, only switch if you can guarantee you will win. Competition lengths will all be 1 or 2.
To summarise, the W-learning walk is similar to a town hall meeting where everyone is agreed except for one person. You can't just ignore their problem, but if they get their way, someone else will be even more annoyed. And so on, and you follow a chain leading who knows where. It would be simple if you could just take a majority vote, but here we're trying to respect individual stories.
If we could make a global decision, the decision we want is probably something like John Rawls' maximin principle from economics [Varian, 1993, §30]. This says that the social welfare of an allocation depends only on the welfare of the worst off agent. In our terminology this would be:
![]()
which would be a fairly sensible method,
although for an agent ![]() to make sure it wins state x,
its strategy has to be to have the lowest absolute Q-values in all the actions other than
to make sure it wins state x,
its strategy has to be to have the lowest absolute Q-values in all the actions other than ![]() to wipe these actions out from the competition.
A single other agent
to wipe these actions out from the competition.
A single other agent ![]() with very low Q-values across the board could spoil its plans.
The creature would end up taking random actions,
controlled by the agent
with very low Q-values across the board could spoil its plans.
The creature would end up taking random actions,
controlled by the agent ![]() that can't score anything anyway.
that can't score anything anyway.
The counterpart is really what we want:
![]()
We call this pure Minimize the Worst Unhappiness. Changing to any other action will cause a worse worst-sufferer. This will choose action (3) above (worst sufferer 0.3). W-learning approximates this when actions are not shared. After the W-learning competition is resolved, changing to the previous action will cause a worse worst-sufferer though changing to some other untried action may not.
In W-learning, an agent is suffering, so we have a change of leader, hopefully to a situation where no one is suffering as much but in fact sometimes to a situation where someone is now suffering more. They will then go into the lead, and so on. Only at the very last change of leader is the worst suffering reduced by the change. Change continues until an optimum is reached where the current worst sufferer cannot be relieved without probably creating an even worse sufferer. The W-learning walk may stop in a local optimum. Minimize the Worst Unhappiness can simply look at the matrix and calculate the global optimum.
And while Negotiated W-learning restricts itself to suggested actions only,
the pure Minimize the Worst Unhappiness may pick a different, compromise action.
It doesn't have to be a compromise
- a single agent can still take over if the differences between its Q-values are big enough,
in which case it can wipe out all actions other than ![]() from the competition.
Like Negotiated W-learning,
Minimize the Worst Unhappiness gives us all the accuracy of the full space without any memory requirements
(as indeed do all the explicit methods where actions are shared).
from the competition.
Like Negotiated W-learning,
Minimize the Worst Unhappiness gives us all the accuracy of the full space without any memory requirements
(as indeed do all the explicit methods where actions are shared).
In short, if agents share the same suite of actions, then taking the Negotiated W-learning walk is of no advantage. Instead we should use the global decision of pure Minimize the Worst Unhappiness.
If agents don't share the same suite of actions, all we can do is repeatedly try things out and observe the unhappiness. We must use W-learning with subspaces or full space to get an approximation of pure Minimize the Worst Unhappiness. Using stochastic highest W, being a simulated-annealing-like process of a high temperature cooling down over time, will make the walk more likely to settle on the global optimum (pure Minimize the Worst Unhappiness) and less likely to stop on some local optimum.
Somehow Negotiated W-learning still seems more plausible than pure Minimize the Worst Unhappiness, since it involves decentralised communication among agents rather than a global-level calculation.
Negotiated W-learning might be better if the number of actions is very large (or continuous) - pure Minimize the Worst Unhappiness has to cycle through them. However, the answer there might be that Minimize the Worst Unhappiness could restrict itself to just the suggested actions (that's what Negotiated W-learning does). And the global decision on these would still be better than the walk:
![]()
Return to Contents page.