There are four basic approaches to organising action selection without reference to a global reward. When the agents share the same set of actions, we can calculate all four approaches immediately. They are:
![]()
This is equivalent to W=Q and can be implemented in that form when actions are not shared (or indeed when they are shared).
![]()
When actions are not shared, this can be approximated by W-learning.
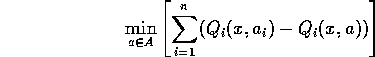
When actions are not shared, this can be approximated by Collective W-learning.
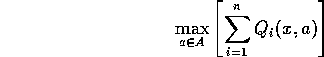
This approach can only be implemented at all if actions are shared. But in fact, Minimize Collective Unhappiness is pretty much the same thing, and that can be approximated by Collective W-learning when actions are not shared.
There are of course other combinations of maximizing, minimizing and summing which do not make any sense. For the full list see §F.
The first approach above has a counterpart discussed in §9. The second approach has a counterpart discussed in §13. The third and fourth approaches are counterparts of each other.
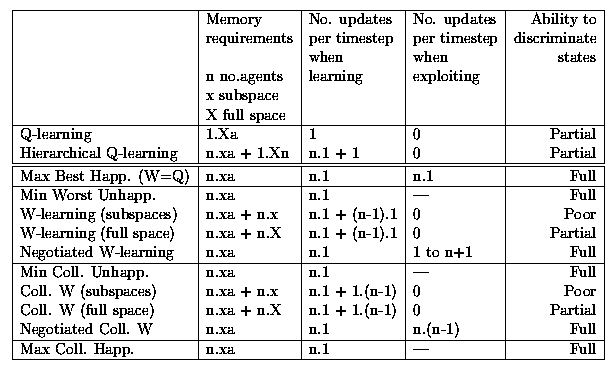
A dash indicates "not applicable" here.
"Number of updates per timestep" is modelled on Watkins [Watkins, 1989] where he wanted to impose limited computational demands on his creature per timestep. The format here is (number of agents) times (updates per agent). We are looking for updates that can be carried out in parallel in isolation.
In the "Ability to discriminate states" column, "Full" indicates complete ability to discern the full state. "Partial" indicates that the ability to discern the full state depends on the generalisation. "Poor" indicates that agents see subspaces only.
Are there any missing methods here? How about W=Q with full space? That would be pointless since that's just Q with full space. The agent will just learn the same Q-values repeated. Similarly, Maximize Collective Happiness with full space is just Q with full space. The W-learning methods are approximations of the approach to which they belong when actions are not shared. In which case, the practical solution is to try out being disobeyed and observe the Unhappiness, as opposed to expanding our action set and learning new Q-values. There is no equivalent of a W-learning method for the Happiness approaches.
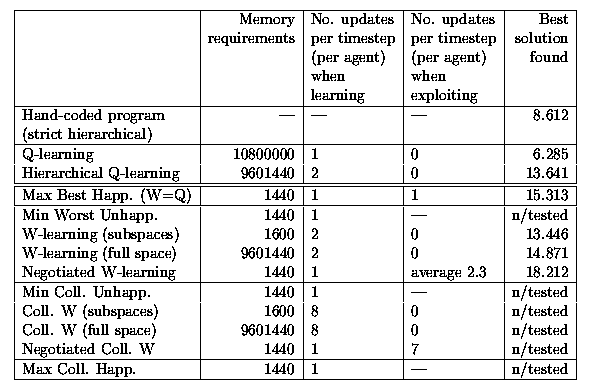
A dash indicates "not applicable" here.
Full details of the experiments, and in particular how we end up comparing a single score for each method, are in §G. For discussion of the spread of scores for each method see §16.3.
Here we show the Number of updates per timestep per agent if the system is totally parallelised (each agent has its own processor). Remember here n = 8 .
Actually for testing Hierarchical Q-learning, I used n = 5 to reduce the size of the Q(x,i) space. The memory requirements shown here are for n = 8 .
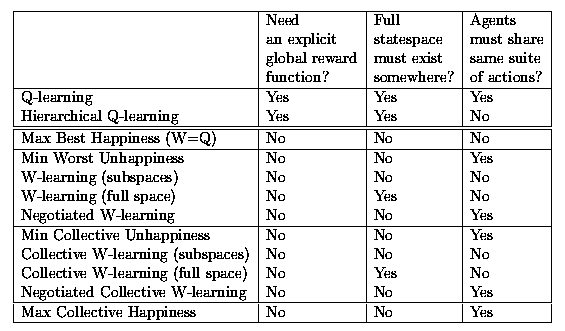
"No" is good here.
There is "no free lunch" in decentralisation. If we want a totally decentralised model, with separate state and action spaces, we have to use either a static method like W=Q, with its inability to support opportunism, or W-learning with subspaces, with its inaccurate competition. In a world where opportunism was more important, W-learning with subspaces wouldn't necessarily be worse than W=Q, as it was here.
The action selection methods can be categorised based on the action they choose:
In fact these are qualified winner-take-all schemes because control may switch from agent to agent per timestep. The winner isn't guaranteed control of the body for some n timesteps.
In W-learning, agents suggest only their favourite actions,
and we pick one of these.
They do not reveal their second or third favourites.
In fact though, with multiple agents all suggesting different actions ![]() ,
something in effect like a search through multiple actions looking for a compromise
may occur (although we do not necessarily
try out even all
,
something in effect like a search through multiple actions looking for a compromise
may occur (although we do not necessarily
try out even all
![]() before getting down to a winner).
before getting down to a winner).
For a compromise action, agents really need to share the same suite of actions
because if they don't share actions, they can't predict how another action will affect them.
All they can do is observe what happens when the action is taken.
And then it would be rather impractical to try out executing every single action a.
W-learning tries out executing only the ![]() 's (and even then, normally only some of them)
before reaching a decision.
's (and even then, normally only some of them)
before reaching a decision.
Consider what an elaborate system we would need to find compromise actions (try out executing every single a) when agents don't share the same set of actions. The leader could execute its second best action. Other agents observe how bad that was, and so on. But we would need to keep a memory, since there is nothing to say that the leader's second best action is better for the other agents - it might be even worse!
Finally, compromise actions are useful for those cases where otherwise we can't avoid total disaster for some agent, but it's important that our scheme doesn't always take a compromise action, otherwise nothing will get completed. It should be just a possibility under the scheme. In Minimize the Worst Unhappiness, one agent can still force the creature to listen to its exact action if it has big enough differences between Q-values for all other actions.
Note that none of these are schemes where the actions of agents are merged. Merging or averaging actions does not make sense in general but only with certain types of actions. For example, see [Scheier and Pfeifer, 1995], where all agents suggest a speed value for the left motor and one for the right motor. These type of actions are amenable to addition and subtraction.
We will attempt to summarise both this chapter and the preceding discussion in one diagram.
Collective methods trample on the individual by trying to keep the majority happy. They are likely both to ruin some individual plans, while at the same time leading to problems with dithering, in which no goal is pursued to its logical end.
W=Q goes to the other extreme in having only one agent in charge, and perhaps suffers because it does not allow opportunism. It won't compromise with the second most needy agent.
W-learning may be a good balance between the two, allowing opportunism without the worst of dithering. One agent is generally in charge, but will be corrected by the other agents whenever it offends them too much. W-learning tries to keep everyone on board, while still going somewhere. For a further analysis of how Minimize the Worst Unhappiness gets tasks completed (enforces persistence) see §15.1.3.
[Maes, 1989, §1] lists desirable criteria for action selection schemes, and in it we see this tension between wanting actions that contribute to several goals at once and yet wanting to stick at goals until their conclusion. We can represent this in a diagram of "single-mindedness" (Figure 14.1).
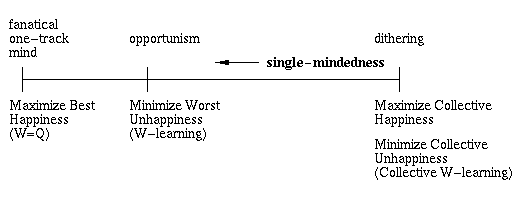
Figure 14.1: The "single-mindedness" of the methods
that organise action selection
without reference to a global reward.
Return to Contents page.