Looking at the summary of empirical results in §14, we note that Q-learning and Hierarchical Q-learning were outperformed by methods that do not refer to the global reward. How could this be? One can see the advantage of self-organising methods if we can't (or don't want to) design an explicit global reward function. But surely if a global reward exists, you can't do better than learning from it.
The answer is that yes, in a Markov Decision Process with lookup tables you can't do better than learning from the global reward. But if the world was that simple, Q-learning would do fine and we wouldn't even be interested in Hierarchical Q-learning let alone any of the self-organising, decentralised methods. It's because we are not in such a simple world that Q-learning (and indeed Hierarchical Q-learning too) can be beaten. [Lin, 1993] has already pointed out that the reason Hierarchical Q-learning beat Q-learning was because Q-learning could not learn the optimal solution in its neural network.
Q-learning and Hierarchical Q-learning suffer from a similar flaw to the Collective methods - they will tend to lose minority agents. Because they use a generalisation, when a reward comes in as part of the global reward function it affects the values of other (x,a) pairs. Small or infrequent rewards can get drowned out by the pursuit of large or frequent rewards. The generalisation learns a cruder policy than is possible with say Negotiated W-learning. It is liable to optimise only the one or two main components of the global reward.
In the self-organising methods, we devolve powers to the agents themselves, allowing rarely used and normally-quiet agents to rise up and take over at crucial, but infrequent, times. Agents can spot better than global functions opportunities to pick up rewards, so devolving power to the agents is a better strategy for keeping them all on board. Minimize the Worst Unhappiness (W-learning) can listen to individual stories in a way that Q-learning and Hierarchical Q-learning cannot.
It is interesting that even simple W=Q was better than Hierarchical Q-learning here.
That large statespace is the problem,
and Lin hasn't found a way of getting rid of it.
It does seem wrong that there should exist such a structure,
for what does it mean?
Is it not merely a number of unrelated observations from different senses combined together.
In Tyrrell's
Simulated Environment [Tyrrell, 1993] the full space would have to be of size ![]() .
Across all our methods, those huge full spaces are mostly wasted.
The two best methods were both with tiny subspaces.
.
Across all our methods, those huge full spaces are mostly wasted.
The two best methods were both with tiny subspaces.
Some of the results were as expected. As expected, Negotiated W-learning was better than W-learning with full space, which itself was better than W-learning with subspaces. W-learning with full space is more accurate than with subspaces, but the neural network means we can't get full accuracy. Negotiated W-learning finally delivers full accuracy.
Also as expected, the results support Lin's basic finding of the advantages of Hierarchical Q-learning over Q-learning.
Finally, while the experiments clearly support decentralisation of some form, there are a number of reasons why they are inconclusive as to what are the very best methods. First of all, the pure version of Minimize the Worst Unhappiness would probably have outperformed Negotiated W-learning and been the best method of all had it been tested. W-learning with full space would probably have performed better than it did had we used a declining Boltzmann for W instead of random W winners (see §10), and so would probably have been next up after these two. Of course these two require agents to share a common suite of actions. If agents don't share actions, W-learning with full space might be the best method. The simple, static W=Q method performed very well, but probably only because opportunism is not important enough in this world (see §9.1). If we were to increase the benefits of opportunism, we might see static W=Q drop to the level of W-learning with subspaces - the two low-memory, inaccurate-competition methods.
The final comment on the experiments is that it is remarkable how difficult it is to hand-code the goal interleaving necessary to perform well in this world. The solutions generated by learning are far superior, though difficult to visualise or translate into a concise set of instructions.
In the much simpler Ant World problem, W-learning with subspaces performed similar to hand-coded programs (see [Humphrys, 1995]), and the statespace was small enough to map, so we could translate the winning strategy into a set of rules (as in §7.1).
In the more complex House Robot problem, hand-coded solutions are far inferior, and at the same time the statespace is too big to map so it is difficult to analyse how the good solutions actually work. Since it is hard to enumerate all the states and see what the system does, it is hard to translate our solution into a concise program. When comparing a state-space versus a set of thousands of IF .. THEN .. rules, one might as well stay with the state-space - it is hardly less comprehensible.
A general comment about the survey of related work (§15). It would be easier to compare action selection methods if the two problems, the "Q-problem" and the "W-problem", were not mixed together. Some of the problems that various action selection methods try to solve are in fact solved by standard methods for single goals, such as short-term loss for long-term gain, which is solved by basic Q-learning. One can't expect one mechanism to do everything. For larger systems, we must separate Q and W or we will drown in complexity.
In fact, it would be helpful if there was a more standard terminology - if all authors, irrespective of whether their scheme was hand-designed, learnt or evolved, used say Q(x,a) for goodness/fitness/utility of an action relative to other actions in an ideal world where the agent acts alone, and W(x) for strength/bid relative to the other agents.
For the four new methods that we tested in this work
(the "global reward function - free" methods)
we ran a Genetic Algorithm search on combinations of rewards ![]() ,
and compared the best solution found by the GA
with the solutions found by Q-learning and Hierarchical Q-learning
(see §G for summary of all experiments).
Is this unfair?
It looks as if we are doing more parameter-tweaking with the four methods
than we allowed for Q-learning and Hierarchical Q-learning.
,
and compared the best solution found by the GA
with the solutions found by Q-learning and Hierarchical Q-learning
(see §G for summary of all experiments).
Is this unfair?
It looks as if we are doing more parameter-tweaking with the four methods
than we allowed for Q-learning and Hierarchical Q-learning.
First of all, remember that here we are trying artificially to compare all the methods on the same scale. So even though the four methods do not need a global reward function to organise their action selection, we still must search for combinations that happen to organise well according to the global reward function's judgement if we are to compare them directly to Q-learning and Hierarchical Q-learning.
Imagine that we have no explicit global reward function. The four methods organise with reference to local rewards only, and then we will have some judgement about the final creature. There are three possible strategies of searching for well-balanced combinations:
In some ways, Strategies 2 and 3 are a search for the global reward function itself. Global reward functions don't come out of thin air, and just because Q-learning and Hierarchical Q-learning have maximized one doesn't mean that the resultant creature has the balanced behavior you want.
Further experiments could be done using Strategies 2 and 3. Using Strategy 1 in this work was good from the point of view of a fair comparison, but bad from other points of view. It gives the impression that a perfect global reward function will normally exist (and hence that we can use Q-learning and Hierarchical Q-learning at all). It also gives the impression that if there is such a function, the four methods take more effort to learn from it than Q-learning and Hierarchical Q-learning do (a full GA search - essentially a search to re-find the global function again). But we didn't have to use a GA - we could have used Strategy 3. The decision not to was again for reasons of a fair test.
Further work could be done with Strategy 1 as well, to analyse the nature of the adaptive landscape that it is exploring. It would be interesting to see how sensitive the performance of the creature could be to small changes in the relative strengths of its competing agents.
The landscape here is hard to illustrate
since it is a 9-dimensional surface (8 parameters leading to 1 fitness value).
Certainly there could be sharp cliffs on the landscape
- there could be some state x which a specific agent ![]() must win
if the creature is to be remotely adaptive.
At the boundary where
must win
if the creature is to be remotely adaptive.
At the boundary where ![]() is just too weak to win the competition for x,
there will be a sharp change in the fitness value.
A sharp peak on the landscape might be less likely than a cliff.
is just too weak to win the competition for x,
there will be a sharp change in the fitness value.
A sharp peak on the landscape might be less likely than a cliff.
Informally, the search space for the GA seemed fairly tractable. The best solutions found levelled off quite rapidly, while the population was continuing to explore diverse points (i.e. this was not simply quick fixation of the whole population at a single local maximum).
More formally, the only proper analysis of the adaptive landscape during this work was, ironically, for the case of the W-learning with subspaces in §4.1 of [Humphrys, 1996] where a badly-designed global reward function caused the optimal behavior to be to jump in and out of the plug non-stop.[1]
For what it's worth, here is an illustration of that landscape. The global reward function was the same as in §4.3.1 except that arrival at the plug scores 1 point. This allowed scores of up to 29.590 points per 100 steps to be achieved. Figure 16.1 shows how quickly the GA finds good solutions.
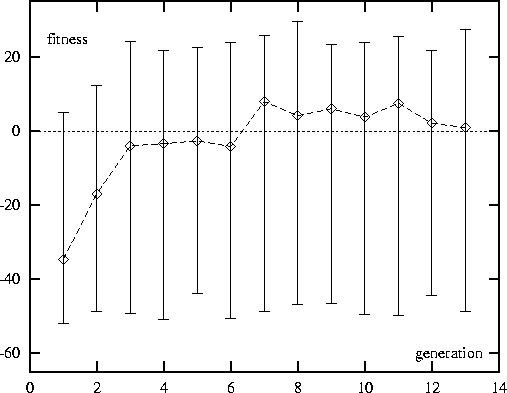
Figure 16.1: The average fitness of the population
for each generation of evolution.
The errorbars show the best and worst individuals in each generation.
To try to understand whether good solutions are clustered together
or scattered on narrow peaks, we need some measure of distance
between two solutions
where solutions are n-dimensional vectors.
The Euclidean distance metric provides such a measure.
Here, given some combination of rewards
![]() ,
the Euclidean distance of this from another combination of rewards
,
the Euclidean distance of this from another combination of rewards
![]() is:
is:
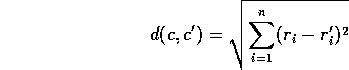
Figure 16.2 shows the Euclidean distance of all solutions
relative to the single best solution
![]() ,
which scored 29.590.
It seems clear that there are multiple peaks with near-optimal solutions
- although there is still some kind of downward slope
as you get very distant from the best point,
so the multiple peaks are to some extent in the same general region of space.
,
which scored 29.590.
It seems clear that there are multiple peaks with near-optimal solutions
- although there is still some kind of downward slope
as you get very distant from the best point,
so the multiple peaks are to some extent in the same general region of space.
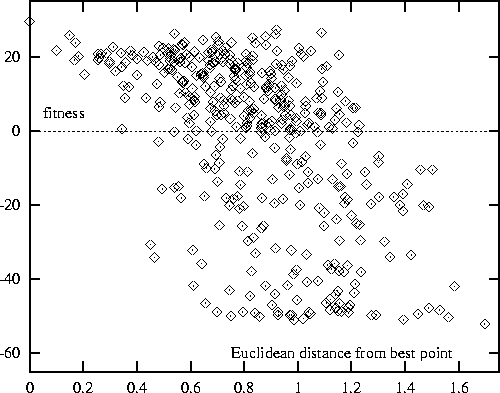
Figure 16.2: A plot of all combinations of rewards tested,
showing the fitness of each combination
plotted against its Euclidean distance from the single best combination.
In fact, we can see that the global maximum cannot be a single point,
it must be a ridge.
Simply multiply all rewards by the same positive constant
and all W-values are multiplied by the constant and the competition is unchanged.
If ![]() , then
, then ![]() .
We get a combination with an identical resolution of competition,
and hence identical fitness,
but at a different point in space
(at a different Euclidean distance).
For example,
.
We get a combination with an identical resolution of competition,
and hence identical fitness,
but at a different point in space
(at a different Euclidean distance).
For example, ![]() would have identical fitness to the best combination here.
Figure 16.2 is probably not a good way to illustrate the landscape then,
since for any high fitness point
we can easily find points of similar fitness
at high Euclidean distance from it.
would have identical fitness to the best combination here.
Figure 16.2 is probably not a good way to illustrate the landscape then,
since for any high fitness point
we can easily find points of similar fitness
at high Euclidean distance from it.
Confusing as this n-dimensional fitness landscape may be, it is the automated search program's job (Strategies 1 and implicitly 2) to navigate it. The searching by hand strategy (Strategy 3) does not deal with a fitness landscape at all, but rather observes behavior.
An agent presents certain Q-values not necessarily because of immediate reward but also because of what is a few steps away. So it may not be much use to the agent to get obeyed now if it won't get obeyed after that and never picks up the reward. Is it possible that in our action selection schemes, an agent is fighting for a state only to never see the long-term rewards that were the reason it wanted the state in the first place?
Say we want to maximise, as the global fitness function for the whole creature, the sum of rewards at each timestep:
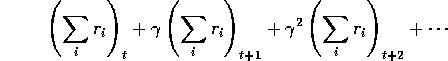
Strangely enough, this does not translate into picking the sum of the Q-values each timestep. Because an agent's Q-value expresses what the agent expects if it takes action a and thereafter follows its own policy. For example, an agent might need to go down a path of a few steps to get its reward:
![]()
So if we follow this agent for under three steps and then switch control,
the sum of rewards it contributes will actually be zero.
Maximising ![]() only translates to
maximising
only translates to
maximising ![]() for the special case
for the special case ![]() .
In general, the sum of the agents' Q-values is a meaningless term because it expresses expected reward
if a number of different policies are followed simultaneously:
.
In general, the sum of the agents' Q-values is a meaningless term because it expresses expected reward
if a number of different policies are followed simultaneously:
![]()
Maximising this sum of the Q-values
may not lead to maximising the sum of the rewards
- it may just lead to dithering.
As we put it in §12.3, it's the whole creature
equivalent of going for short-term gain
at the expense of long-term loss.
The problem arises because agents' Q-values are being optimistic
about what happens if they are obeyed.
For instance, agent ![]() is near its goal.
If obeyed, its Q-value is r, if not
is near its goal.
If obeyed, its Q-value is r, if not ![]() since it can be obeyed on the next step.
The other agents are miles away from their goal.
If obeyed, their Q-value predicts
since it can be obeyed on the next step.
The other agents are miles away from their goal.
If obeyed, their Q-value predicts ![]() since it is being optimistic
that the agent's policy will be followed for n steps afterwards,
which of course it won't be.
If disobeyed, their Q-value is
since it is being optimistic
that the agent's policy will be followed for n steps afterwards,
which of course it won't be.
If disobeyed, their Q-value is ![]() :
:
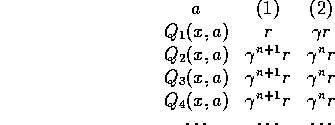
If there are enough other agents, Maximize Collective Happiness will take action (2)
and ![]() will never see its reward.
If there is a similar profile for all the agents - with all of them wanting to go down paths
that none of the others want to go down -
then the same thing will happen to them when they try to get their rewards.
Maximize Collective Happiness, following those optimistic contradictory Q-values,
will always dither and never pick up any actual rewards.
The sum of rewards will be zero, even though we appear to be following the Q-values.
will never see its reward.
If there is a similar profile for all the agents - with all of them wanting to go down paths
that none of the others want to go down -
then the same thing will happen to them when they try to get their rewards.
Maximize Collective Happiness, following those optimistic contradictory Q-values,
will always dither and never pick up any actual rewards.
The sum of rewards will be zero, even though we appear to be following the Q-values.
If we want to maximise the sum of the rewards,
the first solution is of course to simply go back to a global reward function
and a monolithic Q-learner, where the reward each time step is ![]() .
Another solution (discussed in [Whitehead et al., 1993]) is to use a model
to predict what state our Action Selection policy will lead to next,
what decision Action Selection will take then, what state that will lead to, and so on.
Or the Q-values, so as not to be so misleading, would start to express the expected reward
given how we expect to be obeyed in the future
(i.e. we lose the idea of the Q-value expressing something independent of the collection).
Alternatively, perhaps we should
give agents control for a minimum number of timesteps.
.
Another solution (discussed in [Whitehead et al., 1993]) is to use a model
to predict what state our Action Selection policy will lead to next,
what decision Action Selection will take then, what state that will lead to, and so on.
Or the Q-values, so as not to be so misleading, would start to express the expected reward
given how we expect to be obeyed in the future
(i.e. we lose the idea of the Q-value expressing something independent of the collection).
Alternatively, perhaps we should
give agents control for a minimum number of timesteps.
None of these methods is very satisfactory.
In this thesis we can offer instead a local-information, model-free solution
whereby it is a property of the action selection mechanism
that chains of actions from the same agent are likely
to be followed and consummated.
§15.1.3 showed how Minimize the Worst Unhappiness
implements an automatic, positive-feedback, persistence mechanism whereby an agent
that wins a state will be even more likely to win the next state,
and so on until its reward is achieved.
There is much interruption, but it is more likely at some moments than at others.
Goals are followed
and the promised rewards do tend to be picked up before interruption.
Note that W-learning would have allowed ![]() to reach its reward in the example above.
It would have a much higher W-value than any other individual.
to reach its reward in the example above.
It would have a much higher W-value than any other individual.
Our four approaches to action selection all decide competition based only on the current state x and the Q-values the agents have for x. [Whitehead et al., 1993] call this a simple merging strategy, but are too quick to move on to more complex methods without considering what properties a Minimize the Worst Unhappiness simple merging strategy could have.
So we have argued that Minimize the Worst Unhappiness is the best way of maximising the ongoing sum of rewards for the whole creature using local information only - and hence the best way of maximising the sum of rewards at all, since monolithic methods are impractical.
Now we argue that the sum of rewards, or even any linear combination of them (like the global reward function in §4.3.1), cannot fully express the behavior of the whole creature that we want. Because we don't want to see this global score maximised if the solution drops any individual subgoal. We want a good score according to the global reward and at the same time ensure that all subgoals are at some time attended to. This is what is hard to express within the RL framework.
It is difficult to express this constraint in a ![]() distribution
which only considers the current state x.
It is also difficult to express this constraint when we use the global reward function,
as we did here, as a fitness function for a GA,
generating a single numeric fitness score.
If we want to make sure that every subgoal is attended to,
we need to use Strategies 2 or 3 of the previous section,
not Strategy 1.
distribution
which only considers the current state x.
It is also difficult to express this constraint when we use the global reward function,
as we did here, as a fitness function for a GA,
generating a single numeric fitness score.
If we want to make sure that every subgoal is attended to,
we need to use Strategies 2 or 3 of the previous section,
not Strategy 1.
But where does that leave the empirical results of this thesis? We're arguing that maximising the global reward function of §4.3.1 does not define completely how we want the creature to behave. But we argued in favour of our methods because of their success in maximising this global reward function.
In defence of this, first, we presented various examples and analysis to show that our methods will actually take care of individual subgoals where other methods will not. Also, we argued that in this case the reason our methods performed well on the global reward was in fact because they picked up rewards from all the subgoals, whereas monolithic methods learnt a cruder policy. And finally, just because the global test was flawed doesn't mean that the other methods would have performed better under a more ideal global test. Our analysis suggests they would have performed even worse.
It still shows that the comparison of the methods was not ideal though. We used Strategy 1 so that all methods would have a fair comparison. But this was still somewhat unsatisfactory because we lack a way of explicitly penalising methods that ignore subgoals.
Return to Contents page.